AIって結局何なのかよく分からないので、とりあえず100日間勉強してみた Day1
経緯はこちらをご参照ください。
https://hammer-time.org/57/
■本日の進捗
● Pythonではじめる機械学習
1章 はじめに
scikit-learn, Numpy, SciPy, matplotlib, pandas など各種インストール
● Numpyについて勉強
■モチベーション
参考図書は目次を見る限り概要を知る上ではとても優れてそうだが、Numpyやその他モジュールに関する記述は他書に譲っている。モジュール単体で同じ厚さの本が書けるので当たり前と言えば当たり前だが、知識ゼロの状態で使っていくのは気が引けるので、手始めとしてNumpyのユーザーガイド(リファレンス)を一通り読んでみた。
■Numpyとは
“NumPyは、Pythonで科学技術計算をする際の基本的なツールの1つである。多次元配列機能や、線形代数やフーリエ変換、擬似乱数生成器などの、高レベルの数学関数が用意されている。”
Andreas C. Muller, Sarah Guido. Pythonではじめる機械学習. 中田 秀基 訳. オライリー・ジャパン. 2017. 392p.
■注意点
● 動的確保ができるPythonのlist配列とは違い、Numpy配列は静的である(サイズがFixされている)
● Numpy配列の各要素は、メモリサイズを一定に保つことができるが故に同じデータ型を求められる
● 指数・対数関数、Hyperbolic関数等、数学関数ライブラリとしても使える
● 他のPythonベースの数値計算系ライブラリのほとんどがInputおよびOutputでNumpy配列を求めており、もはやPythonを使う上でなくてはならない存在である
■Numpyの何がいいのか
Pythonはよく遅い言語と言われる。可読性が高く記述が直感的なスクリプト言語は概して遅い。これは事実である。
それではPythonで高速に大規模計算を行うにはどうしたらいいだろうか?そこで開発されたのがNumpyである。規則的で型付きの多次元配列にすることでメモリ使用量を削減し、内部コードをC言語とFortranによって記述することで、表面上はPythonだが計算自体はネイティブコード(C言語とFortran)に任せることで、Pythonの処理の遅さによる影響を回避している。
一般的にC言語のようなコンパイル型言語の方が早い。もちろんPythonもメモリ管理が自動化されているなど素晴らしい言語なので誤解のなきよう。
ちなみに機械学習用言語としてPythonの35000倍の処理速度を誇るMojoという新言語があるらしい。(Cより早くね?)
■Numpyの使い方で調べたこと
以降ではすっと理解に入ってこなかった箇所を納得いく形に書き起こしてみた。
●CopyとView
下記のようにViewを作成してその中身を書き換えると、元の配列まで書き換わってしまう。
>>> a = np.array([[1, 2, 3],[4, 5, 6]])
>>> a
array([[1, 2, 3],
[4, 5, 6]])
>>> b = a[1]
>>> b
array([4, 5, 6])
>>> b[0] = 40
>>> b
array([40, 5, 6])
>>> a
array([[ 1, 2, 3],
[40, 5, 6]])厳密には違うものだと前置きしておくが、LinuxのハードリンクやCATIAの挙動を想像していただけると分かりやすいかもしれない。(この手の業界の人は要注意度が身に染みて分かるはず)
ちなみにこの配列がCopyされたものなのかViewなのかはbaseを使えば簡単に分かる。
>>> b.base is None
FalseBase(参照先)はあるよって言ってる。
●配列のsizeとは
>>> a.shape
(2, 3)aは2行3列の配列であることが分かる。
>>> a
array([[ 1, 2, 3],
[40, 5, 6]])
>>> a.size
6その要素数は、1, 2, 3, 40, 5, 6から成る6であり、これがsizeの返り値になる。
●emptyは空じゃない?
過去メモリを見られるのは大変羞恥なのですが、emptyで配列を作るとこのような値が格納された配列が作成される。
>>> np.empty(2)
array([2.05833592e-312, 2.33419537e-312])これは以前その該当メモリに格納されていた値がそのまま残っているからで、emptyをした場合は必ず初期化する必要がある。
●整数のarangeと浮動小数点のlinspace
一般的に大した内容ではないので要点のみ。
np.arrange(開始点, 最大値, ステップ数)で指定でき、整数の配列を作る。ステップ数によっては必ずしも最大値まで行くとは限らない。
np.linspace(開始点, 終了点, num=分割数)で指定でき、開始点と終了点の間を分割してその値を浮動小数点で配列を作る。必ず終了点を含む。
●クイックソート
np.sort(arr):
基本形。arr配列を小さい値から大きい値にソートする。
np.argsort(arr):
arr配列をソートした際の元のインデックスを返す。インデックスとは配列内の要素の位置を示した番号で、基本的に0から始まる。[0, 1, 2, …]
np.lexsort(key1, key2):
複数のキーで辞書式順序に基づいてソートするためのインデックスを返す。…は?
np.searchsorted(arr, values):
values配列がarr配列のどこに挿入されるべきかを位置のインデックスとして返す。
np.partition(arr, k):
arr配列を指定したk番目の位置にある要素を基準にして、それよりも大きいか小さいかでソートする
User Guideによるとlexsortは複数の配列に対して順番にソートするとの記述があり、下記のような例が記載されている。
a = [1, 5, 1, 4, 3, 4, 4] # First sequence
b = [9, 4, 0, 4, 0, 2, 1] # Second sequence
ind = np.lexsort((b, a)) # Sort by 'a', then by 'b'
ind
array([2, 0, 4, 6, 5, 3, 1])
[(a[i], b[i]) for i in ind]
[(1, 0), (1, 9), (3, 0), (4, 1), (4, 2), (4, 4), (5, 4)]https://numpy.org/devdocs/reference/generated/numpy.lexsort.html#numpy.lexsort
numpy.lexsort — NumPy v2.1 Manual
はい、何となく理解しました。最初の配列をソートしてから次の配列をソートするのね。理解、理解。
んで、何に使うんだこれ???
と思いChatGPTってみた。(若者はこれなんて言うん?)
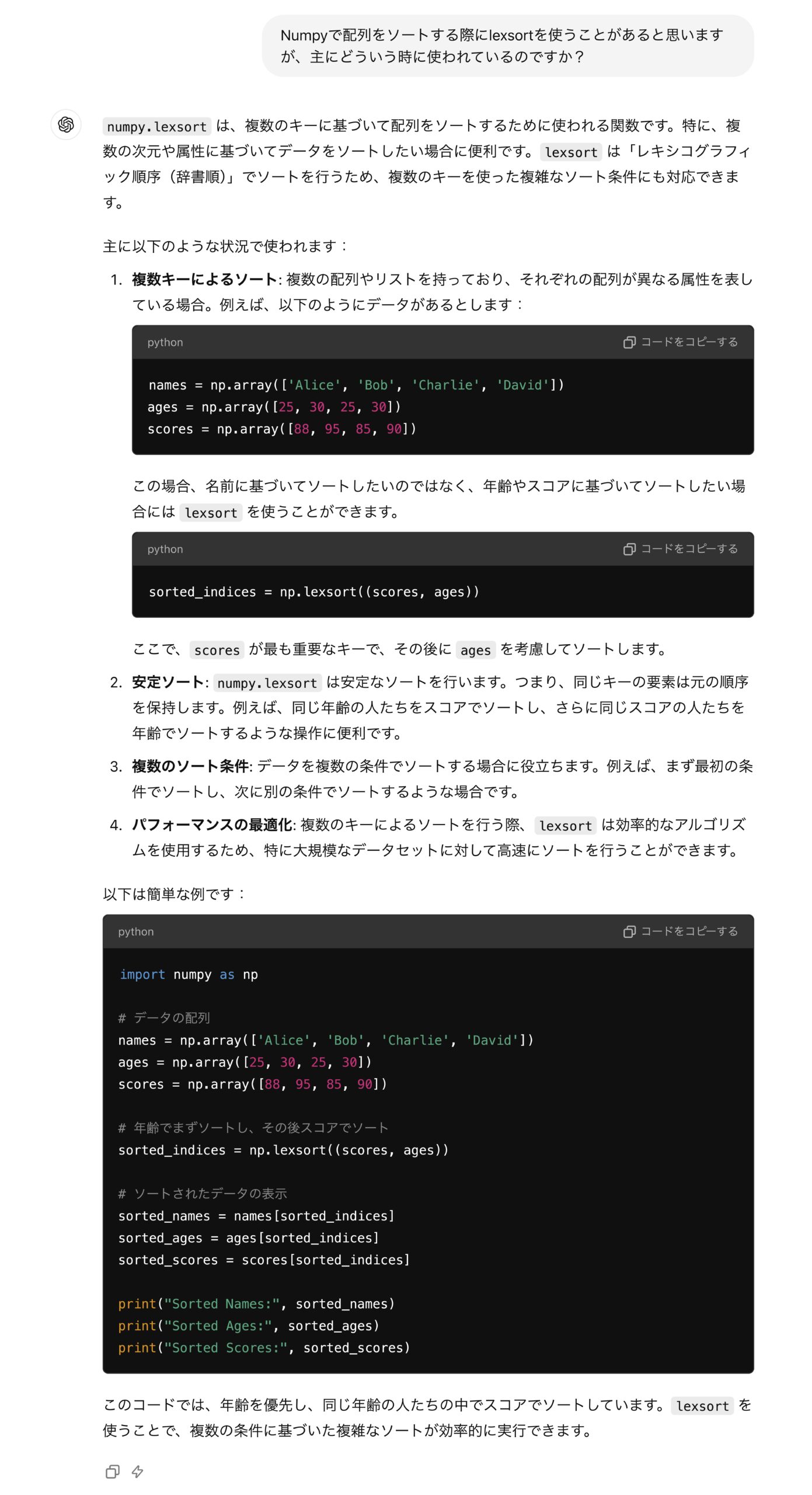
さすが、OpenAI。完璧である。
名前と年齢と得点など、異なるデータ型に対してかなり強力なソート方法になるということが理解できた。lexsortめちゃくちゃ有用じゃん。
■おわりに
残念ながら本日学んだところは以上です。
全然進んでないですが、明日もNumpyの残項目を学んで行きたいと思います。この後はPandasとMatplotlibを同様に学んでから機械学習の方に入っていく予定です。
■参考文献
- Andreas C. Muller, Sarah Guido. Pythonではじめる機械学習. 中田 秀基 訳. オライリー・ジャパン. 2017. 392p.
- NumPy user guide – NumPy v2.1 Manual. numpy.org. 2024.
https://numpy.org/doc/2.1/user/index.html - ChatGPT. 4o mini. OpenAI. 2024.
https://chatgpt.com/