AIって結局何なのかよく分からないので、とりあえず100日間勉強してみた Day37
経緯についてはこちらをご参照ください。
■本日の進捗
●受信者動作特性を理解
●AUCを理解
■はじめに
引き続き「Pythonではじめる機械学習(オライリー・ジャパン)」で学んでいきます。
前回学んだ適合率-再現率カーブに対して、よりクラスが均衡している場合に有効な受動者動作特性カーブとカーブ内領域積分値を示すAUCを導入していきます。
■ROCカーブ
受動者動作特性(receiver operating characteristic:ROC)カーブは、偽陽性率(false positive rate:FPR)と真陽性率(true positive rate:TPR)の変化を示します。
真陽性率は再現率のことで、モデルが正しく陽性と予測できた割合です。
$$ \mathrm{TRP} = \frac{TP}{TP + FN} $$
偽陽性率は、モデルが誤って陽性と予測した割合です。
$$ \mathrm{FPR} = \frac{FP}{FP + TN} $$
これまで用いてきた医療スクリーニング2クラス分類タスク用のデータセットを振り返ります。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
n_samples = 500
n_features = 30
X, y = make_classification(n_samples=n_samples, n_features=n_features,
n_informative=5, n_redundant=10, n_repeated=5,
n_clusters_per_class=1, class_sep=2, flip_y=0.1,
random_state=8)
feature_names = [f"Feature{i}" for i in range(1, n_features+1)]
df = pd.DataFrame(X, columns=feature_names)
df['target'] = y
fig, axes = plt.subplots(nrows=6, ncols=5, figsize=(20, 15))
axes = axes.flatten()
for i, feature in enumerate(feature_names):
axes[i].hist(df[df['target'] == 0][feature], bins=15, color='green', alpha=0.6, label='Class 0')
axes[i].hist(df[df['target'] == 1][feature], bins=15, color='orange', alpha=0.6, label='Class 1')
axes[i].set_title(feature)
axes[i].legend()
plt.tight_layout()
plt.show()
この30の特徴量を持つデータセットに対してロジスティック回帰モデルで学習した結果をROCカーブに描いてみたいと思います。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_predict
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import classification_report, roc_curve, roc_auc_score
n_samples = 500
n_features = 30
X, y = make_classification(n_samples=n_samples, n_features=n_features,
n_informative=5, n_redundant=10, n_repeated=5,
n_clusters_per_class=1, class_sep=2, flip_y=0.1,
random_state=8)
feature_names = [f"Feature{i}" for i in range(1, n_features+1)]
df = pd.DataFrame(X, columns=feature_names)
df['target'] = y
# 本稿では言及しないがちょっとまずい記述なので注意
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
model = LogisticRegression(random_state=8)
y_prob = cross_val_predict(model, X_scaled, y, cv=5, method='predict_proba')
fpr, tpr, _ = roc_curve(y, y_prob[:, 1])
roc_auc = roc_auc_score(y, y_prob[:, 1])
plt.figure(figsize=(8, 6))
plt.plot(fpr, tpr, marker='.', label='ROC curve')
plt.title('ROC Curve')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.grid()
plt.legend()
plt.show()
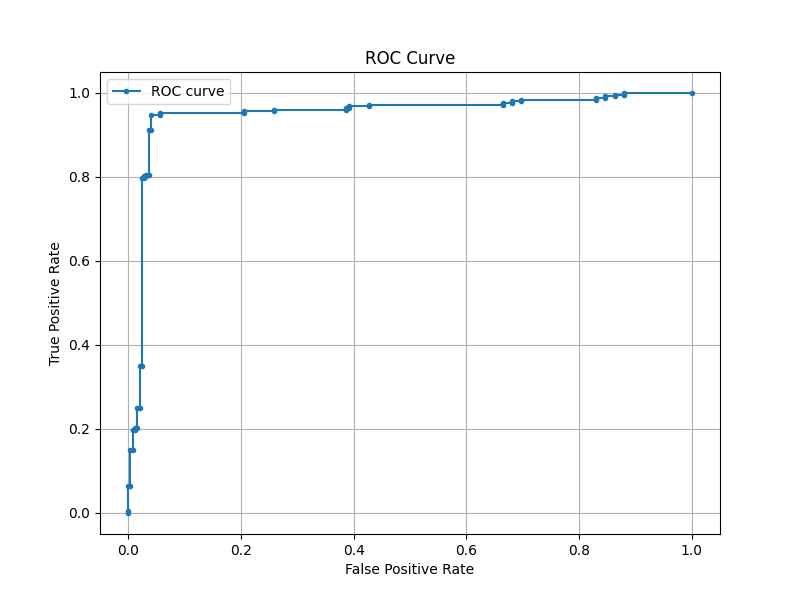
真陽性率が高く偽陽性率が低いモデルが理想的なので、左上に近いほど良いモデルということになります。また、ROCカーブは適合率-再現率カーブと比較して偽陽性率を考慮しているのでより偽陽性を抑制したいモデル(まさに今回のような医療スクリーニングなど)に適しています。
■AUC
AUC(area under the curve)とは、カーブ下の面積のことで、0から1の値を取ります。AUCの値が大きいほど陽性サンプルを正しく陽性に分類し、陰性サンプルを正しく陰性に分類できていることになるので、性能が良いモデルと言えます。
先程のロジスティック回帰で学習させたモデルのAUCを取り出すにはroc_auc_scoreを呼び出せば知ることができます。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_predict
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import classification_report, roc_curve, roc_auc_score
n_samples = 500
n_features = 30
X, y = make_classification(n_samples=n_samples, n_features=n_features,
n_informative=5, n_redundant=10, n_repeated=5,
n_clusters_per_class=1, class_sep=2, flip_y=0.1,
random_state=8)
feature_names = [f"Feature{i}" for i in range(1, n_features+1)]
df = pd.DataFrame(X, columns=feature_names)
df['target'] = y
# 本稿では言及しないがちょっとまずい記述なので注意
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
model = LogisticRegression(random_state=8)
y_prob = cross_val_predict(model, X_scaled, y, cv=5, method='predict_proba')
roc_auc = roc_auc_score(y, y_prob[:, 1])
print('AUC = {:.2f}'.format(roc_auc))
AUC = 0.95■おわりに
今回学んだAUCはクラスが不均衡(現実では寧ろ均衡な方が少ない)なデータセットに対するモデルの予測精度(Accuracy)よりも良い指標になります。
これはただ単に優勢なクラスに分類するだけでもスコアが上がるAccuracyと違って、AUCがその特性上、真陽性率と偽陽性率のトレードオフを反映して評価できるからです。
■参考文献
- Andreas C. Muller, Sarah Guido. Pythonではじめる機械学習. 中田 秀基 訳. オライリー・ジャパン. 2017. 392p.
- ChatGPT. 4o mini. OpenAI. 2024. https://chatgpt.com/
- API Reference. scikit-learn.org. https://scikit-learn.org/stable/api/index.html