AIって結局何なのかよく分からないので、とりあえず100日間勉強してみた Day36
経緯についてはこちらをご参照ください。
■本日の進捗
●適合率-再現率カーブを理解
■はじめに
引き続き「Pythonではじめる機械学習(オライリー・ジャパン)」で学んでいきます。
前回学んだ適合率と再現率を用いて不確実性を考慮に入れた閾値の決定を学んでいきたいと思います。
■不確実性を考慮したより良いモデルを作る
まずは前回作った疑似医療スクリーニング用データセットを正規化してロジスティック回帰に学習させたモデルを振り返ります。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score, confusion_matrix, ConfusionMatrixDisplay, classification_report
n_samples = 500
n_features = 30
X, y = make_classification(n_samples=n_samples, n_features=n_features,
n_informative=5, n_redundant=10, n_repeated=5,
n_clusters_per_class=1, class_sep=2, flip_y=0.1,
random_state=8)
feature_names = [f"Feature{i}" for i in range(1, n_features+1)]
df = pd.DataFrame(X, columns=feature_names)
df['target'] = y
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=8)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
model = LogisticRegression(random_state=8)
model.fit(X_train_scaled, y_train)
y_pred = model.predict(X_test_scaled)
accuracy = accuracy_score(y_test, y_pred)
print('Accuracy: {:.2f}'.format(accuracy))
report = classification_report(y_test, y_pred, target_names=['Class 0', 'Class 1'])
print(report)
Accuracy: 0.98
precision recall f1-score support
Class 0 0.99 0.97 0.98 80
Class 1 0.97 0.99 0.98 70
accuracy 0.98 150
macro avg 0.98 0.98 0.98 150
weighted avg 0.98 0.98 0.98 150まずは公平性のために交差検証を適用してみます。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import classification_report
n_samples = 500
n_features = 30
X, y = make_classification(n_samples=n_samples, n_features=n_features,
n_informative=5, n_redundant=10, n_repeated=5,
n_clusters_per_class=1, class_sep=2, flip_y=0.1,
random_state=8)
feature_names = [f"Feature{i}" for i in range(1, n_features+1)]
df = pd.DataFrame(X, columns=feature_names)
df['target'] = y
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
model = LogisticRegression(random_state=8)
scores = cross_val_score(model, X_scaled, y, cv=5, scoring='accuracy')
print('mean cv score: {:.2f}'.format(np.mean(scores)))
model.fit(X_scaled, y)
y_pred = model.predict(X_scaled)
report = classification_report(y, y_pred, target_names=['Class 0', 'Class 1'])
print(report)
mean cv score: 0.95
precision recall f1-score support
Class 0 0.95 0.96 0.96 248
Class 1 0.96 0.95 0.96 252
accuracy 0.96 500
macro avg 0.96 0.96 0.96 500
weighted avg 0.96 0.96 0.96 500これが現時点のこのモデルの汎化性能と言えます。
今このモデルに必要なのはAccuracyではなく陽性の再現率(Recall)なので、predict_probaを用いて陰性の再現率を犠牲に陽性の再現率を向上させてみます。
import numpy as np
import pandas as pd
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_predict
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import classification_report
n_samples = 500
n_features = 30
X, y = make_classification(n_samples=n_samples, n_features=n_features,
n_informative=5, n_redundant=10, n_repeated=5,
n_clusters_per_class=1, class_sep=2, flip_y=0.1,
random_state=8)
feature_names = [f"Feature{i}" for i in range(1, n_features+1)]
df = pd.DataFrame(X, columns=feature_names)
df['target'] = y
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
model = LogisticRegression(random_state=8)
y_prob = cross_val_predict(model, X_scaled, y, cv=5, method='predict_proba')
threshold = 0.05
y_pred_custom = (y_prob[:, 1] >= threshold).astype(int)
report = classification_report(y, y_pred_custom, target_names=['Class 0', 'Class 1'])
print(report)
precision recall f1-score support
Class 0 0.95 0.58 0.72 248
Class 1 0.70 0.97 0.81 252
accuracy 0.77 500
macro avg 0.82 0.77 0.76 500
weighted avg 0.82 0.77 0.76 500■適合率-再現率カーブ
適合率-再現率カーブ(Precision-Recall Curve)とは、分類モデルにおける適合率と再現率のバランスを可視化するためのものです。
先程のモデルは陽性の再現率を2%上げるのに陰性の再現率を38%犠牲にしました。アプリケーションによってはこの2%がクリティカルな場合もあると思うので、一概に悪いことではないのですが、やはり効率が良いとは言えないように思えます。
このモデルで一番おいしいスイートスポットはどこなのでしょうか。また、陽性再現率を上げるためにどこまで妥協できるでしょうか。こういった調整を行うのに良い指標となる表現方法が適合率-再現率カーブで、precision_recall_curveクラスで簡単に実装することが可能です。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_predict
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import classification_report, precision_recall_curve, average_precision_score
n_samples = 500
n_features = 30
X, y = make_classification(n_samples=n_samples, n_features=n_features,
n_informative=5, n_redundant=10, n_repeated=5,
n_clusters_per_class=1, class_sep=2, flip_y=0.1,
random_state=8)
feature_names = [f"Feature{i}" for i in range(1, n_features+1)]
df = pd.DataFrame(X, columns=feature_names)
df['target'] = y
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
model = LogisticRegression(random_state=8)
y_prob = cross_val_predict(model, X_scaled, y, cv=5, method='predict_proba')
threshold = 0.05
y_pred_custom = (y_prob[:, 1] >= threshold).astype(int)
report = classification_report(y, y_pred_custom, target_names=['Class 0', 'Class 1'])
print(report)
precision, recall, _ = precision_recall_curve(y, y_prob[:, 1])
average_precision = average_precision_score(y, y_prob[:, 1])
plt.figure(figsize=(8, 6))
plt.plot(precision, recall, marker='.', label='Precision-Recall curve')
plt.title('Precision-Recall Curve')
plt.xlabel('Precision')
plt.ylabel('Recall')
plt.grid()
plt.legend()
plt.show()
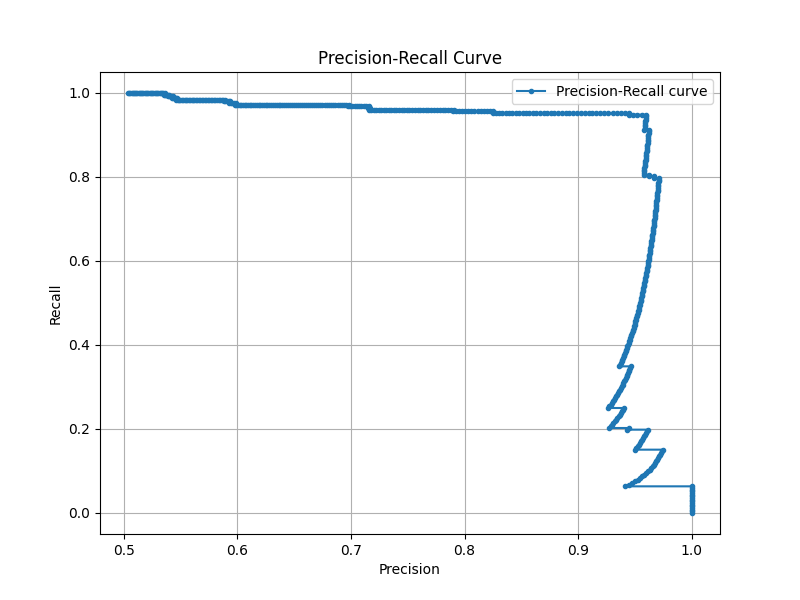
再現率を1.0まで上げると適合率が0.5まで下がり、再現率0.96辺りが最もバランスが良いということが分かります。
■おわりに
あくまで訓練データの中での話ではありますが、再現率を1.0にするのに適合率も0.5は保っていることは、すべての入力データを陽性と返すモデルと比べれば遥かに有用で、スクリーニングのみに用いるのであれば仕事を大幅に減らせるとも考えられます。
必要なf-値は目的に沿って決める必要がありますが、適合率-再現率カーブは良い指標になりそうです。
■参考文献
- Andreas C. Muller, Sarah Guido. Pythonではじめる機械学習. 中田 秀基 訳. オライリー・ジャパン. 2017. 392p.
- ChatGPT. 4o mini. OpenAI. 2024. https://chatgpt.com/
- API Reference. scikit-learn.org. https://scikit-learn.org/stable/api/index.html