AIって結局何なのかよく分からないので、とりあえず100日間勉強してみた Day21
経緯についてはこちらをご参照ください。
■本日の進捗
●凝集型クラスタリングを理解
■はじめに
引き続き「Pythonではじめる機械学習(オライリー・ジャパン)」で学んでいきます。
今回もクラスタリングから階層型クラスタリングの一種である凝集型クラスタリングを学んでいきます。
■凝集型クラスタリング
凝集型クラスタリング(agglomerative clustering)とは、データポイントを個別のクラスタにして、最も似ているクラスタ同士を凝集していき、データを階層的にまとめる手法です。
特徴的なのは最初にデータポイントごとに独立したクラスタを形成することで、データポイントの数だけクラスタが存在することになります。
クラスタ間の最も類似するクラスタを判定する距離測定には連結度(linkage)が用いられ、scikit-learnでも下記のような手法を選択可能です。
・ward法
凝集した際に生じる分散の増加を最小にする方法で、比較的同一サイズのクラスタを形成する
scikit-learnのデフォルト設定
・average法
クラスタ内のすべてのデータポイントの平均距離が最小となるクラスタを連結する
・complete法
クラスタ間の最も遠いデータポイント同士の距離が最小となるクラスタを連結する
このように、凝集型クラスタリングでは距離や結合手法を選択できるため応用が利きます。ただ、全データポイント間で距離を計算するため大規模データにおいては計算に時間がかかる他、ノイズや外れ値からの影響を受けやすいこともあります。
早速、k-meansクラスタリングでも用いたあやめデータセットに凝集型クラスタリングで学習させてみたいと思います。
from sklearn.cluster import AgglomerativeClustering
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
import numpy as np
iris = load_iris()
X = iris.data
model = AgglomerativeClustering(n_clusters=3, linkage='ward')
model.fit(X)
labels = model.labels_
for cluster in np.unique(labels):
cluster_data = X[labels == cluster]
plt.scatter(cluster_data[:, 0], cluster_data[:, 1], label=f'Cluster {cluster + 1}')
plt.title('Agglomerative Clustering with Ward')
plt.xlabel('Sepal Length')
plt.ylabel('Sepal Width')
plt.legend(title="Clusters")
plt.show()
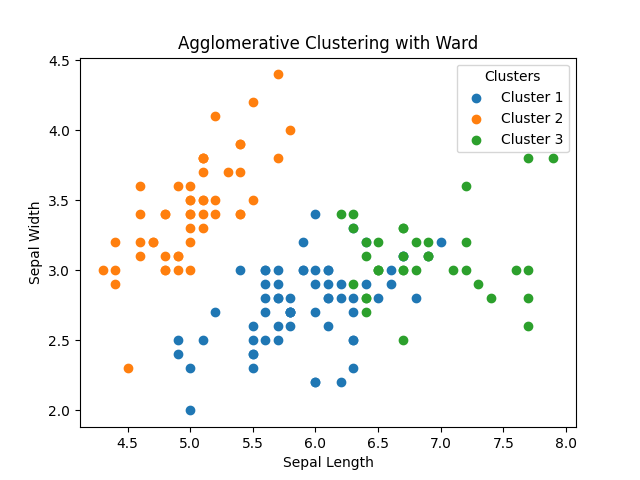
今回もオリジナルデータのクラス分類と比較してみると、やはり密集地帯では正しくクラスタを作れていないものの、setosaに関しては正しく分離できています。また、凝集型クラスタリングも同様にクラスタのラベルには特に意味がないことも理解できます。
■デンドログラム
先ほどの例では、予めあやめデータセットには3つのクラスが存在していることを知っていたので、n_clusters=3を指定しました。scikit-learnの凝集型クラスタリングではn_clusters=2がデフォルトとなっており、何も指定しなければクラスタ数が2つになるまで同じスキーム(今回で言えばward法)を階層的に繰り返します。
では、最終的に収束する適切なクラスタ数を判断する材料がない時はどうすればいいのでしょうか?
そんな時に活躍してくれるのが、デンドログラムと呼ばれる可視化手法です。クラスタリングの階層的なプロセスを視覚化したもので、scikit-learnには実装されていないものの、SciPyのライブラリを用いて表現することができます。
from scipy.cluster.hierarchy import dendrogram, linkage
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
iris = load_iris()
X = iris.data
linked = linkage(X, method='ward')
plt.figure(figsize=(10, 7))
dendrogram(linked, orientation='top', distance_sort='descending', show_leaf_counts=True)
plt.title('Dendrogram (Ward)')
plt.xlabel('Sample index')
plt.ylabel('Distance')
plt.show()
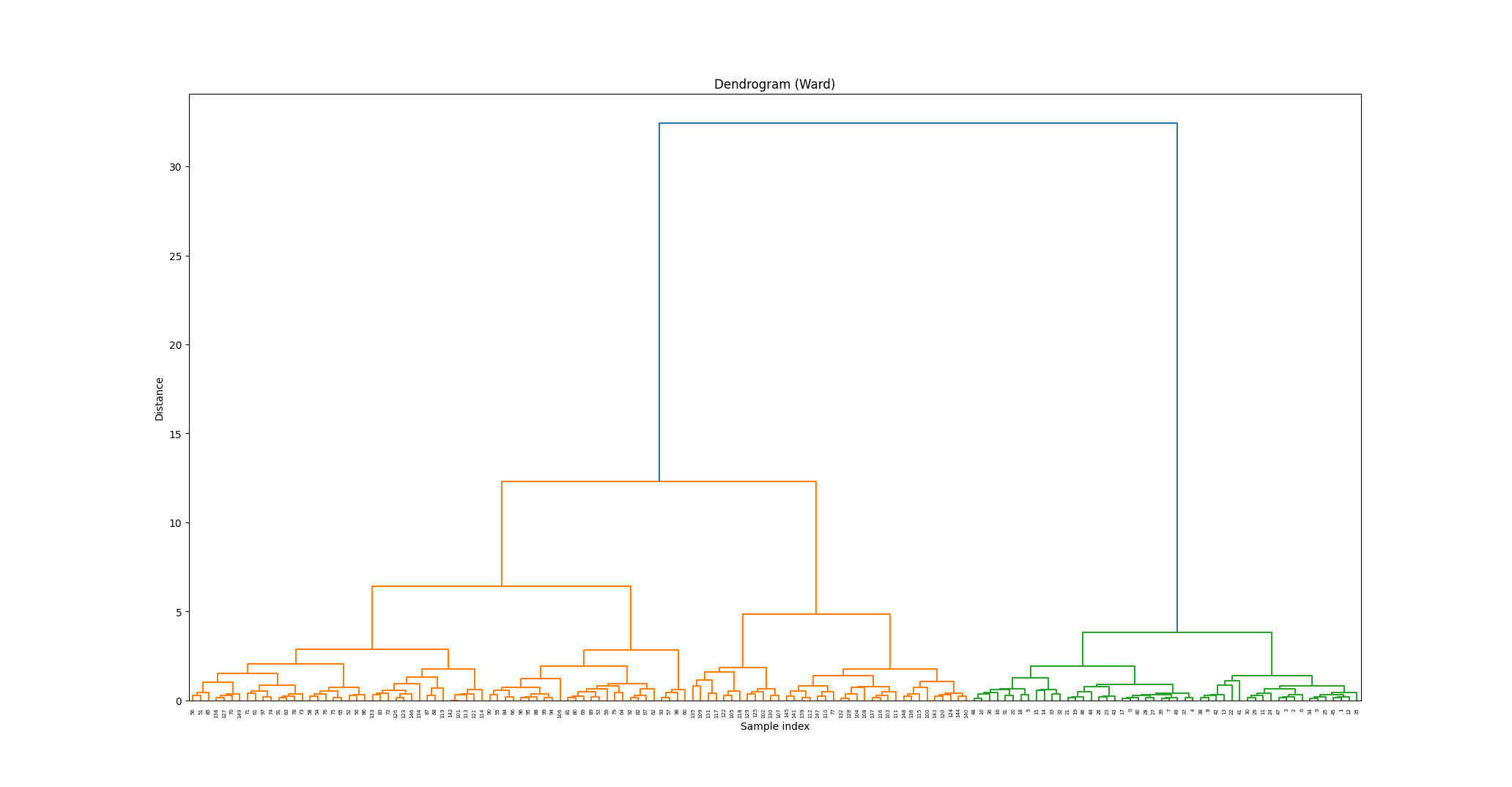
横軸にデータポイントのインデックス、縦軸にクラスタ間の結合距離が表されています。線が長いということは、(一時的にその階層に存在する)クラスタ間の距離が(この場合はward法的に)離れているということです。
このデンドログラムを見る限りは、n_clusters=2が不適切なことが分かると思います。元々答えを知らずとも、n_clusters=3を選択できることでしょう。
この可視化手法はデータセットが大まかにいくつのクラスタに分類できそうかを知るのにとても良い手法です。最終的に凝集型クラスタリングに留まらず、その他手法を試す場合にも、このように事前にクラスタ数に目星をつけることができそうです。
■おわりに
今回は凝集型クラスタリングに初めて触れてみました。これまでの教師なし学習アルゴリズム同様に、それ単体での性能はもちろん、前処理やデータ理解に関しても重要な機能を持っていることを学びました。特に次元削減などの前処理と違い、視覚的にパラメータを事前に設定することができるのはこのような階層型クラスタリングの大きなメリットではないでしょうか。
■参考文献
- Andreas C. Muller, Sarah Guido. Pythonではじめる機械学習. 中田 秀基 訳. オライリー・ジャパン. 2017. 392p.
- ChatGPT. 4o mini. OpenAI. 2024. https://chatgpt.com/
- API Reference. scikit-learn.org. https://scikit-learn.org/stable/api/index.html