AIって結局何なのかよく分からないので、とりあえず100日間勉強してみた Day99
経緯についてはこちらをご参照ください。
■本日の進捗
- seq2seqモデルの学習
■はじめに
今回も「ゼロから作るDeep Learning② 自然言語処理編(オライリー・ジャパン)」から学んでいきます。
今回は、前回学習して足し算の法則を理解しつつあったseq2seqモデルの性能を更に向上させていきます。
■入力データの反転
性能を向上させるための手法として、入力データを反転させるだけで改良できることが知られています。
これは、Encoderが時系列データを順番に処理する際に長い依存関係が伝わりづらく、Decoderに十分な情報を与えられない可能性があります。入力データを反転することで、時系列データの後半(文脈上重要な情報が多い可能性が高い:It is very important)の情報をより濃く残したままEncoderの最終的な隠れ状態を出力でき、より多くの重要な情報を集約してDecoderに渡せます。
実装はとても簡単で、モデルに渡す前に入力データを反転させるだけです。
x_train, x_test = x_train[:, ::-1], x_test[:, ::-1]
下記に学習させた結果を示します。
Q 58+77
T 162
O 162
---
Q 461+579
T 1139
X 1140
---
Q 48+285
T 666
O 666
---
Q 551+8
T 163
O 163
---
Q 55+763
T 422
O 422
---
Q 752+006
T 857
X 856
---
Q 292+167
T 1053
X 1052
---
Q 795+038
T 1427
X 1426
---
Q 838+62
T 864
O 864
---
Q 39+341
T 236
O 236
---
val acc 54.040%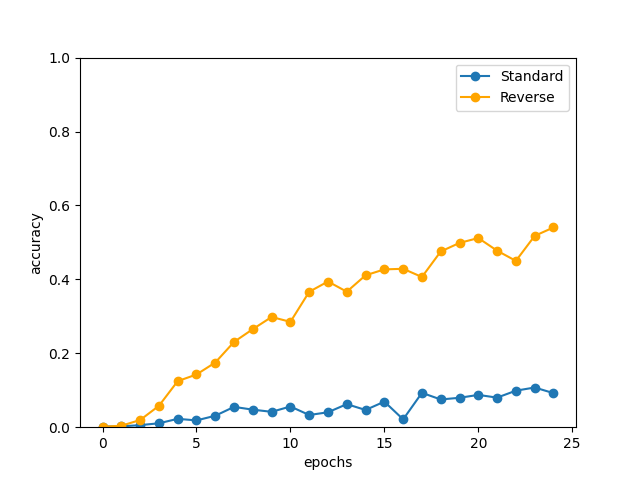
入力データを反転させるだけで大きく性能向上を果たしていることが分かります。
■覗き見(Peeky)
反転だけでも性能向上できましたが、更なる向上のための手法である覗き見(Peeky)手法を適用してみます。
覗き見とは、Encoderが生成する隠れ状態を、通常のDecoderの入力として用いるのに加えて、直接Decoderの隠れ層や出力層に加えることで、隠れ状態の情報をすべてのノードで用いてDecoderの性能を向上させる手法です。
Decoderのすべてのステップで隠れ状態を参照できるように改良します。
構成はほとんど通常のDecoderと同じですが、順伝播の場合にnp.repeat()で隠れ状態を時間方向にT個複製し、その特徴量をEmbedding層の出力とnp.concatenate()で結合してLSTM層の入力にします。
class PeekyDecoder:
def __init__(self, vocab_size, wordvec_size, hidden_size):
V, D, H = vocab_size, wordvec_size, hidden_size
rn = np.random.randn
embed_W = (rn(V, D) / 100).astype('f')
lstm_Wx = (rn(H + D, 4 * H) / np.sqrt(H + D)).astype('f')
lstm_Wh = (rn(H, 4 * H) / np.sqrt(H)).astype('f')
lstm_b = np.zeros(4 * H).astype('f')
affine_W = (rn(H + H, V) / np.sqrt(H + H)).astype('f')
affine_b = np.zeros(V).astype('f')
self.embed = TimeEmbedding(embed_W)
self.lstm = TimeLSTM(lstm_Wx, lstm_Wh, lstm_b, stateful=True)
self.affine = TimeAffine(affine_W, affine_b)
self.params, self.grads = [], []
for layer in (self.embed, self.lstm, self.affine):
self.params += layer.params
self.grads += layer.grads
self.cache = None
def forward(self, xs, h):
N, T = xs.shape
N, H = h.shape
self.lstm.set_state(h)
out = self.embed.forward(xs)
hs = np.repeat(h, T, axis=0).reshape(N, T, H)
out = np.concatenate((hs, out), axis=2)
out = self.lstm.forward(out)
out = np.concatenate((hs, out), axis=2)
score = self.affine.forward(out)
self.cache = H
return score
def backward(self, dscore):
H = self.cache
dout = self.affine.backward(dscore)
dout, dhs0 = dout[:, :, H:], dout[:, :, :H]
dout = self.lstm.backward(dout)
dembed, dhs1 = dout[:, :, H:], dout[:, :, :H]
self.embed.backward(dembed)
dhs = dhs0 + dhs1
dh = self.lstm.dh + np.sum(dhs, axis=1)
return dh
def generate(self, h, start_id, sample_size):
sampled = []
char_id = start_id
self.lstm.set_state(h)
H = h.shape[1]
peeky_h = h.reshape(1, 1, H)
for _ in range(sample_size):
x = np.array([char_id]).reshape((1, 1))
out = self.embed.forward(x)
out = np.concatenate((peeky_h, out), axis=2)
out = self.lstm.forward(out)
out = np.concatenate((peeky_h, out), axis=2)
score = self.affine.forward(out)
char_id = np.argmax(score.flatten())
sampled.append(char_id)
return sampled
Peeky手法を適用した結果を下記に示します。
Q 58+77
T 162
O 162
---
Q 461+579
T 1139
O 1139
---
Q 48+285
T 666
O 666
---
Q 551+8
T 163
O 163
---
Q 55+763
T 422
O 422
---
Q 752+006
T 857
O 857
---
Q 292+167
T 1053
O 1053
---
Q 795+038
T 1427
O 1427
---
Q 838+62
T 864
O 864
---
Q 39+341
T 236
O 236
---
val acc 98.280%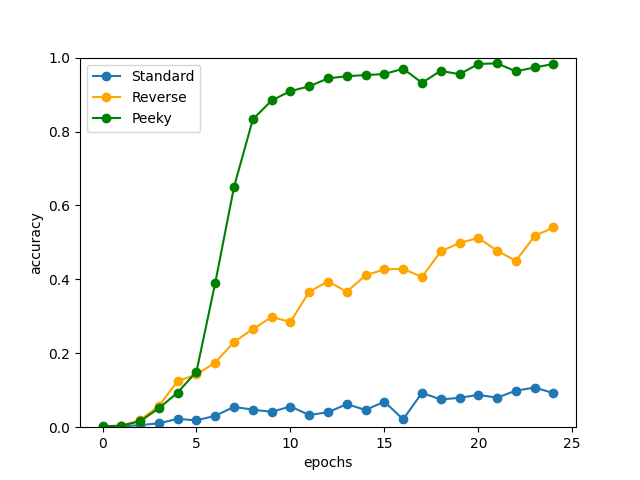
性能は大きく向上しました。seq2seqモデルは足し算の法則性を学習し、ほぼ誤答なく正解を導けられるようになっています。
■おわりに
今回はseq2seqモデルを改良し、可変長の時系列データを精度良く処理できるようになりました。
今回用いた簡単な足し算の問題ですが、生成AIが流行っているこの時代になんでこんな単純計算なんだ?と思っていませんか?実はあらゆる分野の高等な領域まで即答してくれるChatGPTですが、こういった単純な算数が苦手だったことは意外と知られていないみたいです。それはここまであらゆるモデルを試し、再帰型ニューラルネットワークベースの言語モデルを作成してきた中でも起こりえた同様の問題が潜んでいるからです。(GPTはTransformerベースです。)
このような言語モデルは、人間の言語をベースに文字列をベクトルに変換して時系列処理をする性質上、それが高等な数式なのか単純な算数なのかは関係なく、あくまで言語としての答えを推論して返しているに過ぎません。もちろん今回のような可変長の時系列データを扱うことができ、大量の学習を行っているので、今回の計算は軽くこなせるでしょうが、それでも言語モデルにとって得意分野ではないのです。
ちなみにユーザーに暴言を吐いて話題のGoogle Geminiですが、彼らのモデルは数学的な返答には別途計算モデルを用意して答えを返すようにしているため精度が高いのだとか。既に素晴らしい性能を有している各社の言語モデルですが、これからの成長も十分に期待できそうです。
■参考文献
- Andreas C. Muller, Sarah Guido. Pythonではじめる機械学習. 中田 秀基 訳. オライリー・ジャパン. 2017. 392p.
- 斎藤 康毅. ゼロから作るDeep Learning Pythonで学ぶディープラーニングの理論と実装. オライリー・ジャパン. 2016. 320p.
- 斎藤 康毅. ゼロから作るDeep Learning② 自然言語処理編. オライリー・ジャパン. 2018. 432p.
- ChatGPT. 4o mini. OpenAI. 2024. https://chatgpt.com/
- API Reference. scikit-learn.org. https://scikit-learn.org/stable/api/index.html
- PyTorch documentation. pytorch.org. https://pytorch.org/docs/stable/index.html
- Keiron O’Shea, Ryan Nash. An Introduction to Convolutional Neural Networks. https://ar5iv.labs.arxiv.org/html/1511.08458
- API Reference. scipy.org. 2024. https://docs.scipy.org/doc/scipy/reference/index.html