AIって結局何なのかよく分からないので、とりあえず100日間勉強してみた Day98
経緯についてはこちらをご参照ください。
■本日の進捗
- Encoder-Decoder Modelの理解
■はじめに
今回も「ゼロから作るDeep Learning② 自然言語処理編(オライリー・ジャパン)」から学んでいきます。
今回は、前回実装したEncoderクラスとDecoderクラスを用いて、再帰型ニューラルネットワークモデルベースのEncoder-Decoder Modelを構築していきたいと思います。
■seq2seqモデル
seq2seq(sequence-to-sequence)モデルとは、EncoderクラスとDecoderクラスの2つのコンポーネントから構成されるディープラーニングモデルで、時系列データを別の時系列に(つまり入力シーケンスを別のシーケンスに)変換することができます。
基本的な構造は再帰型ニューラルネットワークの場合とほとんど同じで、用いる層がEncoder層やDecoder層になっただけで、順伝播を行って、損失を計算し、逆伝播で勾配を求めるという流れは変わりません。
まずは語彙数(V)、単語埋め込みベクトルの次元数(D)、隠れ状態の次元数(H)を引数として受け取り、Encoder、Decoder、Softmaxを初期化します。
class Seq2seq():
def __init__(self, vocab_size, wordvec_size, hidden_size):
V, D, H = vocab_size, wordvec_size, hidden_size
self.encoder = Encoder(V, D, H)
self.decoder = Decoder(V, D, H)
self.softmax = TimeSoftmaxWithLoss()
self.params = self.encoder.params + self.decoder.params
self.grads = self.encoder.grads + self.decoder.grads
順伝播の場合は、入力シーケンス(xs)とDecoderの教師データとしての出力シーケンス(ts)を引数として受け取り、入力シーケンスをEncoderで隠れ状態(h)に変換、隠れ状態を用いてDecoderでスコアを生成、最後にSoftmaxで損失計算を行います。
def forward(self, xs, ts):
decoder_xs, decoder_ts = ts[:, :-1], ts[:, 1:]
h = self.encoder.forward(xs)
score = self.decoder.forward(decoder_xs, h)
loss = self.softmax.forward(score, decoder_ts)
return loss
逆伝播の場合は、先ほどと逆順で勾配を計算していきます。
def backward(self, dout=1):
dout = self.softmax.backward(dout)
dh = self.decoder.backward(dout)
dout = self.encoder.backward(dh)
return dout
最後にシーケンス生成を行うためのgenerateメソッドを実装します。入力シーケンス(xs)、開始する単語ID(start_id)、生成するシーケンス長さ(sample_size)を引数として受け取り、Encoderで入力シーケンスを隠れ状態(h)に変換してからDecoderのgenerateメソッドでシーケンスを生成します。
def generate(self, xs, start_id, sample_size):
h = self.encoder.forward(xs)
sampled = self.decoder.generate(h, start_id, sample_size)
return sampled
■seq2seqモデルの学習と推論
先程のseq2seqモデルを用いて簡単な足し算を学習させてみせたいと思います。もちろんこのモデルは数字を数値としてではなく文字列として認識するのですが、数字の桁数がいくつのものが入力されるのかが不明で、足し算の結果として桁数がいくつになるのかも変化することになります。こういった可変長の時系列データを扱えるのがこれまでのモデルと違うseq2seqモデルの大きな特徴です。
このような問題は、Toy Problemと呼ばれ、アルゴリズムの検証やパフォーマンスの評価に用いられます。
今回はこの数値データを扱い評価するために下記のリンク先にある外部ライブラリを用いるので別途ご参照ください。
https://github.com/oreilly-japan/deep-learning-from-scratch-2
import sys
import os
sys.path.append('..')
import numpy as np
import matplotlib.pyplot as plt
import pickle
from sklearn.utils.extmath import randomized_svd
import collections
from Encoder_Decoder_class import *
import sequence
GPU = False
class Embedding:
def __init__(self, W):
self.params = [W]
self.grads = [np.zeros_like(W)]
self.idx = None
def forward(self, idx):
W, = self.params
self.idx = idx
out = W[idx]
return out
def backward(self, dout):
dW, = self.grads
dW[...] = 0
if GPU:
np.scatter_add(dW, self.idx, dout)
else:
np.add.at(dW, self.idx, dout)
return None
def softmax(x):
if x.ndim == 2:
x = x - x.max(axis=1, keepdims=True)
x = np.exp(x)
x /= x.sum(axis=1, keepdims=True)
elif x.ndim == 1:
x = x - np.max(x)
x = np.exp(x) / np.sum(np.exp(x))
return x
def sigmoid(x):
return 1 / (1 + np.exp(-x))
class LSTM:
def __init__(self, Wx, Wh, b):
self.params = [Wx, Wh, b]
self.grads = [np.zeros_like(Wx), np.zeros_like(Wh), np.zeros_like(b)]
self.cache = None
def forward(self, x, h_prev, c_prev):
Wx, Wh, b = self.params
N, H = h_prev.shape
A = np.dot(x, Wx) + np.dot(h_prev, Wh) + b
f = A[:, :H]
g = A[:, H:2*H]
i = A[:, 2*H:3*H]
o = A[:, 3*H:]
f = sigmoid(f)
g = np.tanh(g)
i = sigmoid(i)
o = sigmoid(o)
c_next = f * c_prev + g * i
h_next = o * np.tanh(c_next)
self.cache = (x, h_prev, c_prev, i, f, g, o, c_next)
return h_next, c_next
def backward(self, dh_next, dc_next):
Wx, Wh, b = self.params
x, h_prev, c_prev, i, f, g, o, c_next = self.cache
tanh_c_next = np.tanh(c_next)
ds = dc_next + (dh_next * o) * (1 - tanh_c_next ** 2)
dc_prev = ds * f
di = ds * g
df = ds * c_prev
do = dh_next * tanh_c_next
dg = ds * i
di *= i * (1 - i)
df *= f * (1 - f)
do *= o * (1 - o)
dg *= (1 - g ** 2)
dA = np.hstack((df, dg, di, do))
dWh = np.dot(h_prev.T, dA)
dWx = np.dot(x.T, dA)
db = dA.sum(axis=0)
self.grads[0][...] = dWx
self.grads[1][...] = dWh
self.grads[2][...] = db
dx = np.dot(dA, Wx.T)
dh_prev = np.dot(dA, Wh.T)
return dx, dh_prev, dc_prev
class TimeLSTM:
def __init__(self, Wx, Wh, b, stateful=False):
self.params = [Wx, Wh, b]
self.grads = [np.zeros_like(Wx), np.zeros_like(Wh), np.zeros_like(b)]
self.layers = None
self.h, self.c = None, None
self.dh = None
self.stateful = stateful
def forward(self, xs):
Wx, Wh, b = self.params
N, T, D = xs.shape
H = Wh.shape[0]
self.layers = []
hs = np.empty((N, T, H), dtype='f')
if not self.stateful or self.h is None:
self.h = np.zeros((N, H), dtype='f')
if not self.stateful or self.c is None:
self.c = np.zeros((N, H), dtype='f')
for t in range(T):
layer = LSTM(*self.params)
self.h, self.c = layer.forward(xs[:, t, :], self.h, self.c)
hs[:, t, :] = self.h
self.layers.append(layer)
return hs
def backward(self, dhs):
Wx, Wh, b = self.params
N, T, H = dhs.shape
D = Wx.shape[0]
dxs = np.empty((N, T, D), dtype='f')
dh, dc = 0, 0
grads = [0, 0, 0]
for t in reversed(range(T)):
layer = self.layers[t]
dx, dh, dc = layer.backward(dhs[:, t, :] + dh, dc)
dxs[:, t, :] = dx
for i, grad in enumerate(layer.grads):
grads[i] += grad
for i, grad in enumerate(grads):
self.grads[i][...] = grad
self.dh = dh
return dxs
def set_state(self, h, c=None):
self.h, self.c = h, c
def reset_state(self):
self.h, self.c = None, None
class TimeEmbedding:
def __init__(self, W):
self.params = [W]
self.grads = [np.zeros_like(W)]
self.layers = None
self.W = W
def forward(self, xs):
N, T = xs.shape
V, D = self.W.shape
out = np.empty((N, T, D), dtype='f')
self.layers = []
for t in range(T):
layer = Embedding(self.W)
out[:, t, :] = layer.forward(xs[:, t])
self.layers.append(layer)
return out
def backward(self, dout):
N, T, D = dout.shape
grad = 0
for t in range(T):
layer = self.layers[t]
layer.backward(dout[:, t, :])
grad += layer.grads[0]
self.grads[0][...] = grad
return None
class TimeAffine:
def __init__(self, W, b):
self.params = [W, b]
self.grads = [np.zeros_like(W), np.zeros_like(b)]
self.x = None
def forward(self, x):
N, T, D = x.shape
W, b = self.params
rx = x.reshape(N*T, -1)
out = np.dot(rx, W) + b
self.x = x
return out.reshape(N, T, -1)
def backward(self, dout):
x = self.x
N, T, D = x.shape
W, b = self.params
dout = dout.reshape(N*T, -1)
rx = x.reshape(N*T, -1)
db = np.sum(dout, axis=0)
dW = np.dot(rx.T, dout)
dx = np.dot(dout, W.T)
dx = dx.reshape(*x.shape)
self.grads[0][...] = dW
self.grads[1][...] = db
return dx
class TimeSoftmaxWithLoss:
def __init__(self):
self.params, self.grads = [], []
self.cache = None
self.ignore_label = -1
def forward(self, xs, ts):
N, T, V = xs.shape
if ts.ndim == 3:
ts = ts.argmax(axis=2)
mask = (ts != self.ignore_label)
xs = xs.reshape(N * T, V)
ts = ts.reshape(N * T)
mask = mask.reshape(N * T)
ys = softmax(xs)
ls = np.log(ys[np.arange(N * T), ts])
ls *= mask
loss = -np.sum(ls)
loss /= mask.sum()
self.cache = (ts, ys, mask, (N, T, V))
return loss
def backward(self, dout=1):
ts, ys, mask, (N, T, V) = self.cache
dx = ys
dx[np.arange(N * T), ts] -= 1
dx *= dout
dx /= mask.sum()
dx *= mask[:, np.newaxis]
dx = dx.reshape((N, T, V))
return dx
class Encoder:
def __init__(self, vocab_size, wordvec_size, hidden_size):
V, D, H = vocab_size, wordvec_size, hidden_size
rn = np.random.randn
embed_W = (rn(V, D) / 100).astype('f')
lstm_Wx = (rn(D, 4 * H) / np.sqrt(D)).astype('f')
lstm_Wh = (rn(H, 4 * H) / np.sqrt(H)).astype('f')
lstm_b = np.zeros(4 * H).astype('f')
self.embed = TimeEmbedding(embed_W)
self.lstm = TimeLSTM(lstm_Wx, lstm_Wh, lstm_b, stateful=False)
self.params = self.embed.params + self.lstm.params
self.grads = self.embed.grads + self.lstm.grads
self.hs = None
def forward(self, xs):
xs = self.embed.forward(xs)
hs = self.lstm.forward(xs)
self.hs = hs
return hs[:, -1, :]
def backward(self, dh):
dhs = np.zeros_like(self.hs)
dhs[:, -1, :] = dh
dout = self.lstm.backward(dhs)
dout = self.embed.backward(dout)
return dout
class Decoder:
def __init__(self, vocab_size, wordvec_size, hidden_size):
V, D, H = vocab_size, wordvec_size, hidden_size
rn = np.random.randn
embed_W = (rn(V, D) / 100).astype('f')
lstm_Wx = (rn(D, 4 * H) / np.sqrt(D)).astype('f')
lstm_Wh = (rn(H, 4 * H) / np.sqrt(H)).astype('f')
lstm_b = np.zeros(4 * H).astype('f')
affine_W = (rn(H, V) / np.sqrt(H)).astype('f')
affine_b = np.zeros(V).astype('f')
self.embed = TimeEmbedding(embed_W)
self.lstm = TimeLSTM(lstm_Wx, lstm_Wh, lstm_b, stateful=True)
self.affine = TimeAffine(affine_W, affine_b)
self.params, self.grads = [], []
for layer in (self.embed, self.lstm, self.affine):
self.params += layer.params
self.grads += layer.grads
def forward(self, xs, h):
self.lstm.set_state(h)
out = self.embed.forward(xs)
out = self.lstm.forward(out)
score = self.affine.forward(out)
return score
def backward(self, dscore):
dout = self.affine.backward(dscore)
dout = self.lstm.backward(dout)
dout = self.embed.backward(dout)
dh = self.lstm.dh
return dh
def generate(self, h, start_id, sample_size):
sampled = []
sample_id = start_id
self.lstm.set_state(h)
for _ in range(sample_size):
x = np.array(sample_id).reshape((1, 1))
out = self.embed.forward(x)
out = self.lstm.forward(out)
score = self.affine.forward(out)
sample_id = np.argmax(score.flatten())
sampled.append(int(sample_id))
return sampled
class Seq2seq():
def __init__(self, vocab_size, wordvec_size, hidden_size):
V, D, H = vocab_size, wordvec_size, hidden_size
self.encoder = Encoder(V, D, H)
self.decoder = Decoder(V, D, H)
self.softmax = TimeSoftmaxWithLoss()
self.params = self.encoder.params + self.decoder.params
self.grads = self.encoder.grads + self.decoder.grads
def forward(self, xs, ts):
decoder_xs, decoder_ts = ts[:, :-1], ts[:, 1:]
h = self.encoder.forward(xs)
score = self.decoder.forward(decoder_xs, h)
loss = self.softmax.forward(score, decoder_ts)
return loss
def backward(self, dout=1):
dout = self.softmax.backward(dout)
dh = self.decoder.backward(dout)
dout = self.encoder.backward(dh)
return dout
def generate(self, xs, start_id, sample_size):
h = self.encoder.forward(xs)
sampled = self.decoder.generate(h, start_id, sample_size)
return sampled
(x_train, t_train), (x_test, t_test) = sequence.load_data('addition.txt')
char_to_id, id_to_char = sequence.get_vocab()
vocab_size = len(char_to_id)
wordvec_size = 16
hidden_size = 128
batch_size = 128
max_epoch = 25
max_grad = 5.0
model = Seq2seq(vocab_size, wordvec_size, hidden_size)
optimizer = Adam()
trainer = Trainer(model, optimizer)
acc_list = []
for epoch in range(max_epoch):
trainer.fit(x_train, t_train, max_epoch=1,
batch_size=batch_size, max_grad=max_grad)
correct_num = 0
for i in range(len(x_test)):
question, correct = x_test[[i]], t_test[[i]]
verbose = i < 10
correct_num += eval_seq2seq(model, question, correct,
id_to_char, verbose, is_reverse)
acc = float(correct_num) / len(x_test)
acc_list.append(acc)
print('val acc %.3f%%' % (acc * 100))
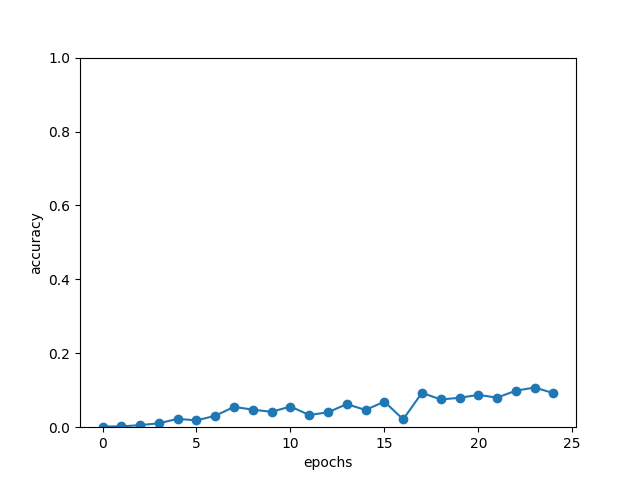
x = np.arange(len(acc_list))
plt.plot(x, acc_list, marker='o')
plt.xlabel('epochs')
plt.ylabel('accuracy')
plt.ylim(0, 1.0)
plt.show()
Epoch1の結果
Q 77+85
T 162
X 100
---
Q 975+164
T 1139
X 1000
---
Q 582+84
T 666
X 1000
---
Q 8+155
T 163
X 100
---
Q 367+55
T 422
X 1000
---
Q 600+257
T 857
X 1000
---
Q 761+292
T 1053
X 1000
---
Q 830+597
T 1427
X 1000
---
Q 26+838
T 864
X 1000
---
Q 143+93
T 236
X 100
---
val acc 0.180%Epoch25の結果
Q 77+85
T 162
X 161
---
Q 975+164
T 1139
O 1139
---
Q 582+84
T 666
X 662
---
Q 8+155
T 163
X 164
---
Q 367+55
T 422
X 419
---
Q 600+257
T 857
X 849
---
Q 761+292
T 1053
X 1049
---
Q 830+597
T 1427
X 1419
---
Q 26+838
T 864
X 852
---
Q 143+93
T 236
X 242
---
val acc 9.220%■おわりに
seq2seqモデルで足し算を学習させてみました。教師データと比較して正答率で評価していますが、若干の学習はできているものの十分ではなさそうです。上記に表示させた中では、正答できたのは975+164だけでした。
■参考文献
- Andreas C. Muller, Sarah Guido. Pythonではじめる機械学習. 中田 秀基 訳. オライリー・ジャパン. 2017. 392p.
- 斎藤 康毅. ゼロから作るDeep Learning Pythonで学ぶディープラーニングの理論と実装. オライリー・ジャパン. 2016. 320p.
- 斎藤 康毅. ゼロから作るDeep Learning② 自然言語処理編. オライリー・ジャパン. 2018. 432p.
- ChatGPT. 4o mini. OpenAI. 2024. https://chatgpt.com/
- API Reference. scikit-learn.org. https://scikit-learn.org/stable/api/index.html
- PyTorch documentation. pytorch.org. https://pytorch.org/docs/stable/index.html
- Keiron O’Shea, Ryan Nash. An Introduction to Convolutional Neural Networks. https://ar5iv.labs.arxiv.org/html/1511.08458
- API Reference. scipy.org. 2024. https://docs.scipy.org/doc/scipy/reference/index.html