AIって結局何なのかよく分からないので、とりあえず100日間勉強してみた Day81
経緯についてはこちらをご参照ください。
■本日の進捗
- skip-gramを理解
■はじめに
今回も「ゼロから作るDeep Learning② 自然言語処理編(オライリー・ジャパン)」から学んでいきます。
今回は、CBoWと対を成すword2vecのもう一つのモデル構造であるskip-gramを学んでいきます。
■skip-gram
skip-gramは自然言語処理における単語の分散表現を学習するための手法で、word2vecで提案されたアルゴリズムの一つです。CBoWでは周囲のコンテキストからターゲットの単語を予測していましたが、skip-gramではターゲットの単語から周囲のコンテキストを予測します。
ターゲット単語をwt、コンテキストを周囲1単語とすると、wtがあるときにwt-1とwt+1が同時に起こる確率は次のように表せます。
$$ \mathrm{P}(w_{t-1}, w_{t+1} | w_t) $$
コンテキストの間に関連性がないと仮定すれば、
$$ \mathrm{P}(w_{t-1}, w_{t+1} | w_t) = \mathrm{P}(w_{t-1} | w_t) \mathrm{P}(w_{t+1}|w_t) $$
この時の損失は、交差エントロピー誤差を用いて、
$$ L \ = \ – \log \mathrm{P}(w_{t-1}, w_{t+1} | w_t) $$
$$ \ \ \ \ \ \ \ \ \ = \ – \log \mathrm{P}(w_{t-1} | w_t) \mathrm{P}(w_{t+1}|w_t) $$
$$ \ \ \ \ \ \ \ \ \ \ \ \ \ \ = \ – (\log \mathrm{P}(w_{t-1} | w_t) + \mathrm{P}(w_{t+1}|w_t)) $$
コーパス全体に拡張すれば、
$$ L = -\frac{1}{T} \sum_{t=1}^T (\log \mathrm{P}(w_{t-1} | w_t) + \mathrm{P}(w_{t+1}|w_t)) $$
それではskip-gramを実装してみます。
import numpy as np
import matplotlib.pyplot as plt
class MatMul:
def __init__(self, W):
self.params = [W]
self.grads = [np.zeros_like(W)]
self.x = None
def forward(self, x):
W, = self.params
out = np.dot(x, W)
self.x = x
return out
def backward(self, dout):
W, = self.params
dx = np.dot(dout, W.T)
dW = np.dot(self.x.T, dout)
self.grads[0][...] = dW
return dx
class SoftmaxCrossEntropy:
def __init__(self):
self.output = None
self.y_true = None
self.loss = None
def forward(self, logits, y_true):
exp_values = np.exp(logits - np.max(logits, axis=1, keepdims=True))
self.output = exp_values / np.sum(exp_values, axis=1, keepdims=True)
self.y_true = y_true
self.loss = -np.sum(y_true * np.log(self.output + 1e-7)) / y_true.shape[0]
return self.loss
def backward(self):
return (self.output - self.y_true) / self.y_true.shape[0]
def cross_entropy_error(y, t):
delta = 1e-7
return -np.sum(t * np.log(y + delta)) / y.shape[0]
class Adam:
def __init__(self, lr=0.001, beta1=0.9, beta2=0.999):
self.lr = lr
self.beta1 = beta1
self.beta2 = beta2
self.iter = 0
self.m = None
self.v = None
def update(self, params, grads):
if self.m is None:
self.m, self.v = {}, {}
for key, val in params.items():
self.m[key] = np.zeros_like(val)
self.v[key] = np.zeros_like(val)
self.iter += 1
lr_t = self.lr * np.sqrt(1.0 - self.beta2 ** self.iter) / (1.0 - self.beta1 ** self.iter)
for key in params.keys():
self.m[key] = self.beta1 * self.m[key] + (1 - self.beta1) * grads[key]
self.v[key] = self.beta2 * self.v[key] + (1 - self.beta2) * (grads[key] ** 2)
params[key] -= lr_t * self.m[key] / (np.sqrt(self.v[key]) + 1e-7)
def preprocess(text):
text = text.lower()
text = text.replace('.', ' .')
words = text.split(' ')
word_to_id = {}
id_to_word = {}
for word in words:
if word not in word_to_id:
new_id = len(word_to_id)
word_to_id[word] = new_id
id_to_word[new_id] = word
corpus = np.array([word_to_id[w] for w in words])
return corpus, word_to_id, id_to_word
def convert_one_hot(corpus, vocab_size):
N = corpus.shape[0]
if corpus.ndim == 1:
one_hot = np.zeros((N, vocab_size), dtype=np.int32)
for idx, word_id in enumerate(corpus):
one_hot[idx, word_id] = 1
elif corpus.ndim == 2:
C = corpus.shape[1]
one_hot = np.zeros((N, C, vocab_size), dtype=np.int32)
for idx_0, word_id in enumerate(corpus):
for idx_1, word_id in enumerate(word_id):
one_hot[idx_0, idx_1, word_id] = 1
return one_hot
def create_contexts_target(corpus, window_size=1):
target = corpus[window_size:-window_size]
contexts = []
for idx in range(window_size, len(corpus)-window_size):
cs = []
for t in range(-window_size, window_size + 1):
if t == 0:
continue
cs.append(corpus[idx + t])
contexts.append(cs)
return np.array(contexts), np.array(target)
class SimpleCBoW:
def __init__(self, vocab_size, hidden_size):
V, H = vocab_size, hidden_size
W_in = 0.01 * np.random.randn(V, H).astype('f')
W_out = 0.01 * np.random.randn(H, V).astype('f')
self.layers = [
MatMul(W_in),
MatMul(W_out)
]
self.loss_layer = SoftmaxCrossEntropy()
self.params, self.grads = [], []
for layer in self.layers:
self.params += layer.params
self.grads += layer.grads
self.word_vecs = W_in
def forward(self, contexts, target):
h0 = self.layers[0].forward(contexts[:, 0])
h1 = self.layers[0].forward(contexts[:, 1])
h = (h0 + h1) * 0.5
score = self.layers[1].forward(h)
loss = self.loss_layer.forward(score, target)
return loss
def backward(self, dout=1):
ds = self.loss_layer.backward()
da = self.layers[1].backward(ds)
da *= 0.5
self.layers[0].backward(da)
return None
class SimpleSkipGram:
def __init__(self, vocab_size, hidden_size):
V, H = vocab_size, hidden_size
W_in_0 = 0.0001 * np.random.randn(V, H).astype('f')
W_in_1 = 0.0001 * np.random.randn(V, H).astype('f')
W_out = 0.0001 * np.random.randn(H, V).astype('f')
self.layers = [
MatMul(W_in_0),
MatMul(W_in_1),
MatMul(W_out)
]
self.loss_layer = SoftmaxCrossEntropy()
self.params, self.grads = [], []
for layer in self.layers:
self.params += layer.params
self.grads += layer.grads
self.param_dict = {
'W_in_0': self.params[0],
'W_in_1': self.params[1],
'W_out': self.params[2]
}
self.grad_dict = {
'W_in_0': self.grads[0],
'W_in_1': self.grads[1],
'W_out': self.grads[2]
}
self.word_vecs = W_in_0
reg_lambda = 1e-4
self.reg_lambda = reg_lambda
def forward(self, contexts, target):
h0 = self.layers[0].forward(contexts[:, 0])
h1 = self.layers[1].forward(contexts[:, 1])
h = (h0 + h1) * 0.5
s = self.layers[2].forward(h)
l1 = self.loss_layer.forward(s, contexts[:, 0])
l2 = self.loss_layer.forward(s, contexts[:, 1])
loss = l1 + l2
loss += self.reg_lambda * (np.sum(self.param_dict['W_in_0']**2) + np.sum(self.param_dict['W_in_1']**2) + np.sum(self.param_dict['W_out']**2))
return loss
def backward(self, dout=1):
dl1 = self.loss_layer.backward()
dl2 = self.loss_layer.backward()
ds = dl1 + dl2
dh = self.layers[2].backward(ds)
self.layers[0].backward(dh)
self.layers[1].backward(dh)
return None
window_size = 1
hidden_size = 5
batch_size = 5
max_epoch = 1000
text = 'You say goodbye and I say hello.'
corpus, word_to_id, id_to_word = preprocess(text)
vocab_size = len(word_to_id)
contexts, target = create_contexts_target(corpus, window_size)
target = convert_one_hot(target, vocab_size)
contexts = convert_one_hot(contexts, vocab_size)
model = SimpleSkipGram(vocab_size, hidden_size)
optimizer = Adam(lr=0.0001)
params = model.param_dict
grads = model.grad_dict
losses = []
for epoch in range(max_epoch):
idx = np.random.choice(len(contexts), batch_size)
contexts_batch = contexts[idx]
target_batch = target[idx]
loss = model.forward(contexts_batch, target_batch)
losses.append(loss)
model.backward()
optimizer.update(params, grads)
if epoch % 100 == 0:
print(f"Epoch {epoch}, Loss: {loss}")
plt.plot(range(max_epoch), losses)
plt.xlabel('Iterations')
plt.ylabel('Loss')
plt.title('NeuralNetBased SimpleSkipGram learning')
plt.show()
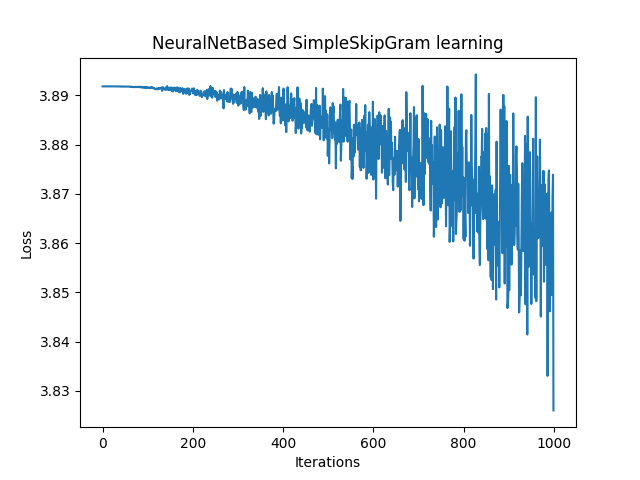
損失の収束性はとても悪く発散しかけていますが、これはコーパスが極めて小規模であることが原因である可能性があります。
CBoWでは複数のコンテキストからターゲットを推測するので、少ないデータでも有用なパターンを学習しやすく比較的損失が減少しやすい傾向があります。
SkipGramではこれとは逆に1つのターゲットから周りにある複数のコンテキストを推測するので、小規模なコーパスでは学習するための文脈が少なく必要な情報が不足しがちになります。このため極端に小さいコーパスでは損失の収束が遅かったり十分に学習できない可能性があります。
■おわりに
今回はSkipGramを用いたニューラルネットワークを実装し、簡単なコーパスを学習させてみました。前述の通り、CBoWでは何とか学習できていた極めて小規模なコーパスに対して、SkipGramではほとんど学習ができていなかったです。
この問題はコーパスを大きくすれば改善するかもしれませんし、パラメータを調整する必要もあるかもしれません。そしてあるいはプログラムの若干の修正も必要になる可能性はもちろんあります。
■参考文献
- Andreas C. Muller, Sarah Guido. Pythonではじめる機械学習. 中田 秀基 訳. オライリー・ジャパン. 2017. 392p.
- 斎藤 康毅. ゼロから作るDeep Learning Pythonで学ぶディープラーニングの理論と実装. オライリー・ジャパン. 2016. 320p.
- 斎藤 康毅. ゼロから作るDeep Learning② 自然言語処理編. オライリー・ジャパン. 2018. 432p.
- ChatGPT. 4o mini. OpenAI. 2024. https://chatgpt.com/
- API Reference. scikit-learn.org. https://scikit-learn.org/stable/api/index.html
- PyTorch documentation. pytorch.org. https://pytorch.org/docs/stable/index.html
- Keiron O’Shea, Ryan Nash. An Introduction to Convolutional Neural Networks. https://ar5iv.labs.arxiv.org/html/1511.08458
- API Reference. scipy.org. 2024. https://docs.scipy.org/doc/scipy/reference/index.html