AIって結局何なのかよく分からないので、とりあえず100日間勉強してみた Day68
経緯についてはこちらをご参照ください。
■本日の進捗
- Dropoutを理解
■はじめに
今回も「ゼロから作るDeep Learning Pythonで学ぶディープラーニングの理論と実装(オライリー・ジャパン)」で、深層学習を学んでいきます。
今回はWeight decayよりも更にニューラルネットワークに適した過学習を抑制する手法であるDropoutを導入してみます。
■Dropout
Dropout(ランダム正規化)とは、ニューラルネットワークの過学習を抑制する正規化手法の一つで、ランダムに選んだニューロンを消去しながら学習することで、モデルが特定の特徴量に過度に依存しないようにします。
学習時にはDropout層のニューロンをランダムに無効化し出力も勾配も計算せず、無効化されなかったニューロンにはDropout率に応じて出力がスケーリングされ影響を補正します。
推論時にはすべてのニューロンを有効化しますが、学習時のスケーリング影響を考慮した出力の調整が行われます。
各ニューロンのマスクrは、ベルヌーイ分布に従って、
$$ r_i \sim \mathrm{Bernoulli}(1 – p) $$
Dropoutの出力は、各ニューロンの出力hを用いて、
$$ \tilde{h}_i = r_i \cdot h_i $$
となります。
早速ニューラルネットワークに実装してみます。
import sys
import numpy as np
import matplotlib.pyplot as plt
sys.path.append("./")
from work.mnist import load_mnist
class ReLU:
def __init__(self):
self.mask = None
def forward(self, x):
self.mask = (x <= 0)
out = np.maximum(0, x)
return out
def backward(self, dout):
dout[self.mask] = 0
dx = dout
return dx
class Affine:
def __init__(self, W, b):
self.W = W
self.b = b
self.x = None
self.dW = None
self.db = None
def forward(self, x):
self.x = x
out = np.dot(x, self.W) + self.b
return out
def backward(self, dout):
self.dW = np.dot(self.x.T, dout)
self.db = np.sum(dout, axis=0)
dx = np.dot(dout, self.W.T)
return dx
class Dropout:
def __init__(self, dropout_ratio):
self.dropout_ratio = dropout_ratio
self.mask = None
def forward(self, x, train_flg=True):
if train_flg:
self.mask = np.random.rand(*x.shape) > self.dropout_ratio
return x * self.mask
else:
return x * (1.0 - self.dropout_ratio)
def backward(self, dout):
return dout * self.mask
class SoftmaxCrossEntropy:
def __init__(self):
self.output = None
self.grad_input = None
def forward(self, logits):
exp_values = np.exp(logits - np.max(logits, axis=1, keepdims=True))
self.output = exp_values / np.sum(exp_values, axis=1, keepdims=True)
return self.output
def backward(self, y_true):
self.grad_input = self.output - y_true
return self.grad_input
def cross_entropy_error(y, t):
delta = 1e-7
return -np.sum(t * np.log(y + delta)) / y.shape[0]
class NeuralNetworkWithDropout:
def __init__(self, input_size, hidden_size, output_size, weight_init_std=0.01, dropout_ratio=0.5):
self.params = {}
self.params['W1'] = weight_init_std * np.random.randn(input_size, hidden_size)
self.params['b1'] = np.zeros(hidden_size)
self.params['W2'] = weight_init_std * np.random.randn(hidden_size, hidden_size)
self.params['b2'] = np.zeros(hidden_size)
self.params['W3'] = weight_init_std * np.random.randn(hidden_size, output_size)
self.params['b3'] = np.zeros(output_size)
self.layers = [
Affine(self.params['W1'], self.params['b1']),
ReLU(),
Dropout(dropout_ratio),
Affine(self.params['W2'], self.params['b2']),
ReLU(),
Dropout(dropout_ratio),
Affine(self.params['W3'], self.params['b3'])
]
self.loss_layer = SoftmaxCrossEntropy()
def forward(self, x, train_flg=True):
for layer in self.layers:
if isinstance(layer, Dropout):
x = layer.forward(x, train_flg)
else:
x = layer.forward(x)
return x
def compute_loss(self, x, y_true, train_flg=True):
logits = self.forward(x, train_flg)
loss = cross_entropy_error(self.loss_layer.forward(logits), y_true)
return loss
def backward(self, y_true):
dout = self.loss_layer.backward(y_true)
for layer in reversed(self.layers):
dout = layer.backward(dout)
def update(self, lr):
for layer in self.layers:
if isinstance(layer, Affine):
layer.W -= lr * layer.dW
layer.b -= lr * layer.db
def accuracy(self, x, y_true):
logits = self.forward(x, train_flg=False)
y_pred = np.argmax(logits, axis=1)
y_true_labels = np.argmax(y_true, axis=1)
accuracy = np.mean(y_pred == y_true_labels)
return accuracy
(X_train, y_train), (X_test, y_test) = load_mnist(normalize=True, one_hot_label=True)
train_size = X_train.shape[0]
batch_size = 100
epochs = 10
lr = 0.001
input_size = 784
hidden_size = 200
output_size = 10
dropout_ratio = 0.5
network = NeuralNetworkWithDropout(input_size, hidden_size, output_size, dropout_ratio=dropout_ratio)
train_accuracy_history = []
test_accuracy_history = []
for epoch in range(epochs):
for _ in range(train_size // batch_size):
batch_mask = np.random.choice(train_size, batch_size)
X_batch = X_train[batch_mask]
y_batch = y_train[batch_mask]
network.compute_loss(X_batch, y_batch)
network.backward(y_batch)
network.update(lr)
train_accuracy = network.accuracy(X_train, y_train)
test_accuracy = network.accuracy(X_test, y_test)
train_accuracy_history.append(train_accuracy)
test_accuracy_history.append(test_accuracy)
print(f"Epoch {epoch+1}, Train Accuracy: {train_accuracy}, Test Accuracy: {test_accuracy}")
plt.plot(range(1, epochs + 1), train_accuracy_history, label="Train Accuracy", color="orange")
plt.plot(range(1, epochs + 1), test_accuracy_history, label="Test Accuracy", color="green")
plt.xlabel("Epoch")
plt.ylabel("Accuracy")
plt.ylim(0.1, 1.0)
plt.title("Backpropagation SGD with Dropout")
plt.legend()
plt.show()
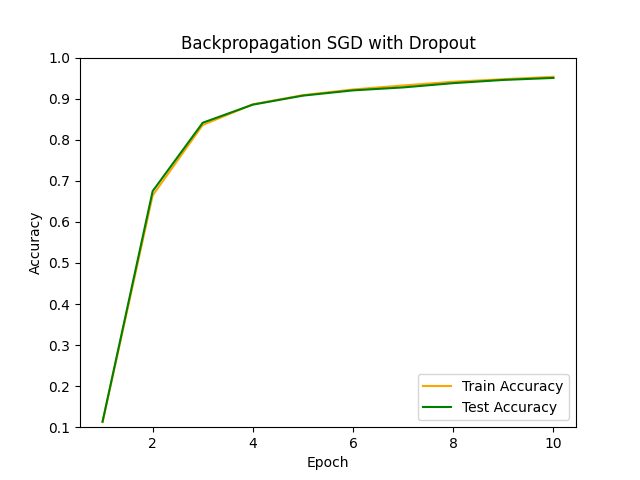
Dropoutを用いない基本的なSGDでの学習と比較してみます。
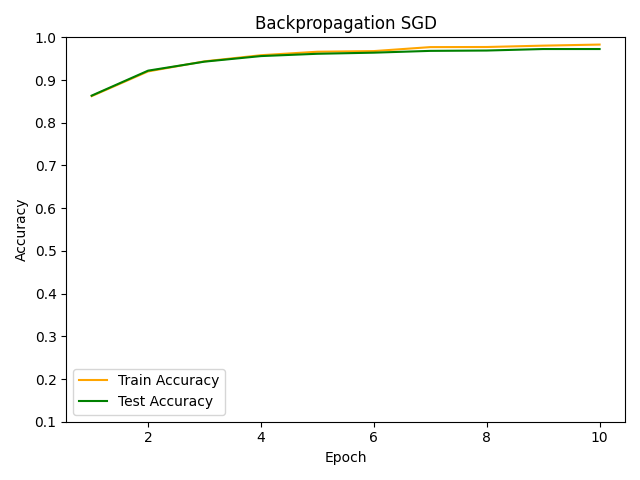
基本的なSGDの場合は過学習気味ですが、Dropout層を入れることでその傾向がだいぶ抑制されていることが確認できます。
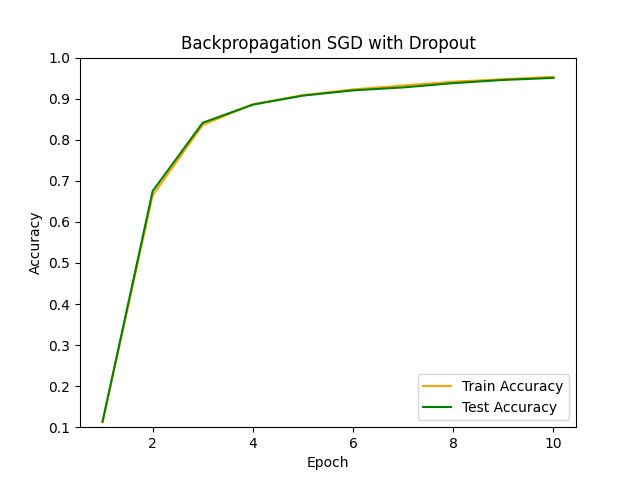
最後にDropout率をいくつか変更してその挙動を見てみます。

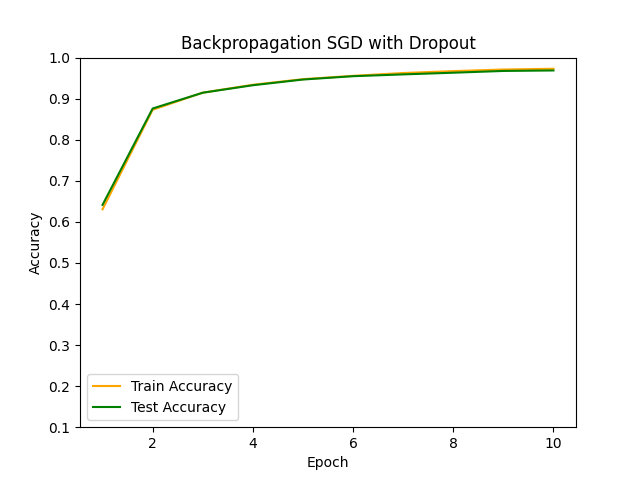
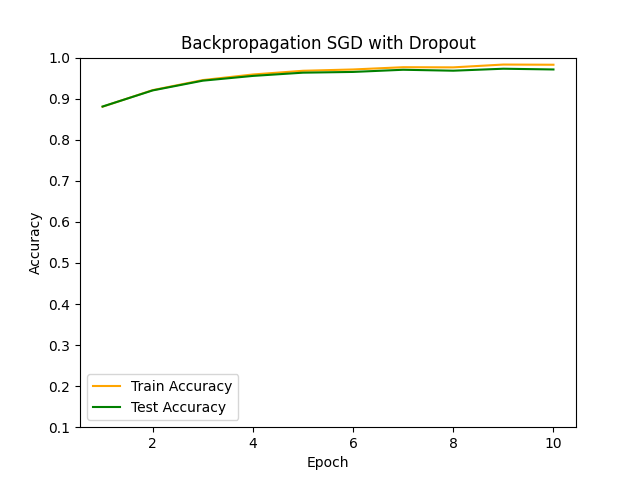
■おわりに
今回はDropoutを実装してみました。そのアルゴリズムはそれほど難しくはないですが、ニューロンを無効化するという大胆な手法のおかげで高い過学習抑制効果を得られています。
また、Weight decayと同様に、パラメータ(Dropout率)を0にすることでDropout手法自体を無効化することもできますし、もちろんDropout層を入れるかどうかでも調整ができます。入れておいて損はないのではないでしょうか。
■参考文献
- Andreas C. Muller, Sarah Guido. Pythonではじめる機械学習. 中田 秀基 訳. オライリー・ジャパン. 2017. 392p.
- 斎藤 康毅. ゼロから作るDeep Learning Pythonで学ぶディープラーニングの理論と実装. オライリー・ジャパン. 2016. 320p.
- ChatGPT. 4o mini. OpenAI. 2024. https://chatgpt.com/
- API Reference. scikit-learn.org. https://scikit-learn.org/stable/api/index.html
- PyTorch documentation. pytorch.org. https://pytorch.org/docs/stable/index.html
- Nitish Sricastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, Ruslan Salakhutdinov. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. 2014. Journal of Machine Learning Research 15