AIって結局何なのかよく分からないので、とりあえず100日間勉強してみた Day33
経緯についてはこちらをご参照ください。
■本日の進捗
●Meta Estimatorを理解
■はじめに
引き続き「Pythonではじめる機械学習(オライリー・ジャパン)」で学んでいきます。
前回学んだ単純なグリッドサーチを応用して、交差検証付きグリッドサーチを学んでいきます。
■交差検証を用いたグリッドサーチ
単純なグリッドサーチでは、ハイパーパラメータに対して任意の範囲で単一の訓練データとテストデータを用いたモデル構築と評価を繰り返し、最良の結果を得るパラメータの組み合わせを探索していました。
しかしこの場合の問題点は、得られたパラメータの組み合わせが「単一のデータ」に対しての最適解に過ぎないことでした。この問題は単にscoreを用いたモデルの評価の時と同じもので、交差検証を適用することでデータに対するバイアスを解消できることを学びました。
グリッドサーチなどのハイパーパラメータ探索手法に対してそのモデル構築や評価にも交差検証を用いれば、前述の通りバイアスを減らせて汎化性能があるパラメータの組み合わせを探索できそうです。
この交差検証を用いたグリッドサーチは単に交差検証とも呼ばれ、パラメータ探索手法では広く採用されている手法でもあります。
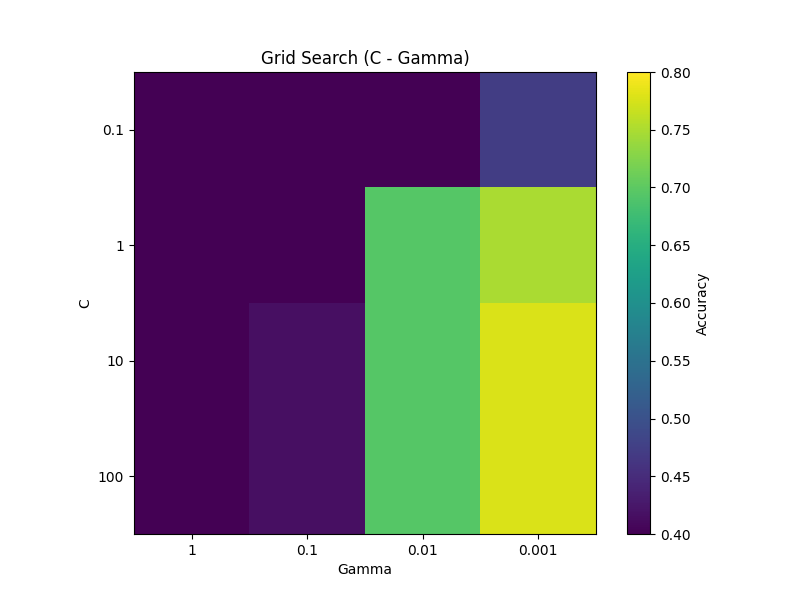
まずはワインデータセットに対する単純なパラメータ探索を振り返ります。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_wine
data = load_wine()
X, y = data.data, data.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=8)
param_grid = {
'C': [0.1, 1, 10, 100],
'gamma': [1, 0.1, 0.01, 0.001]
}
scores = []
for C in param_grid['C']:
row = []
for gamma in param_grid['gamma']:
model = SVC(C=C, gamma=gamma, kernel='rbf')
model.fit(X_train, y_train)
score = model.score(X_test, y_test)
row.append(score)
scores.append(row)
scores = np.array(scores)
plt.figure(figsize=(8, 6))
plt.imshow(scores, interpolation='nearest', cmap='viridis', vmin=0.4, vmax=0.8)
plt.title('Grid Search (C - Gamma)')
plt.xlabel('Gamma')
plt.ylabel('C')
plt.xticks(np.arange(len(param_grid['gamma'])), param_grid['gamma'])
plt.yticks(np.arange(len(param_grid['C'])), param_grid['C'])
plt.colorbar(label='Accuracy')
plt.show()
単純なグリッドサーチはfor文で簡単に実装できますが、交差検証を用いたグリッドサーチもscikit-learnであればGridSearchCVクラスを用いて簡単に実装可能です。(むしろ単純な場合よりも遥かに簡単です。)
import numpy as np
import matplotlib.pyplot as plt
from sklearn.svm import SVC
from sklearn.model_selection import GridSearchCV, train_test_split
from sklearn.datasets import load_wine
data = load_wine()
X, y = data.data, data.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=8)
param_grid = {
'C': [0.1, 1, 10, 100],
'gamma': [1, 0.1, 0.01, 0.001]
}
grid = GridSearchCV(SVC(kernel='rbf'), param_grid, refit=True, cv=5, verbose=0)
grid.fit(X_train, y_train)
score = grid.score(X_test, y_test)
print(f"Best parameters: {grid.best_params_}")
print(f"Test set score: {score}")
scores = grid.cv_results_['mean_test_score'].reshape(len(param_grid['C']), len(param_grid['gamma']))
plt.figure(figsize=(8, 6))
plt.imshow(scores, interpolation='nearest', cmap='viridis', vmin=0.4, vmax=0.8)
plt.title('Grid Search CV (C - Gamma)')
plt.xlabel('Gamma')
plt.ylabel('C')
plt.xticks(np.arange(len(param_grid['gamma'])), param_grid['gamma'])
plt.yticks(np.arange(len(param_grid['C'])), param_grid['C'])
plt.colorbar(label='Accuracy')
plt.show()
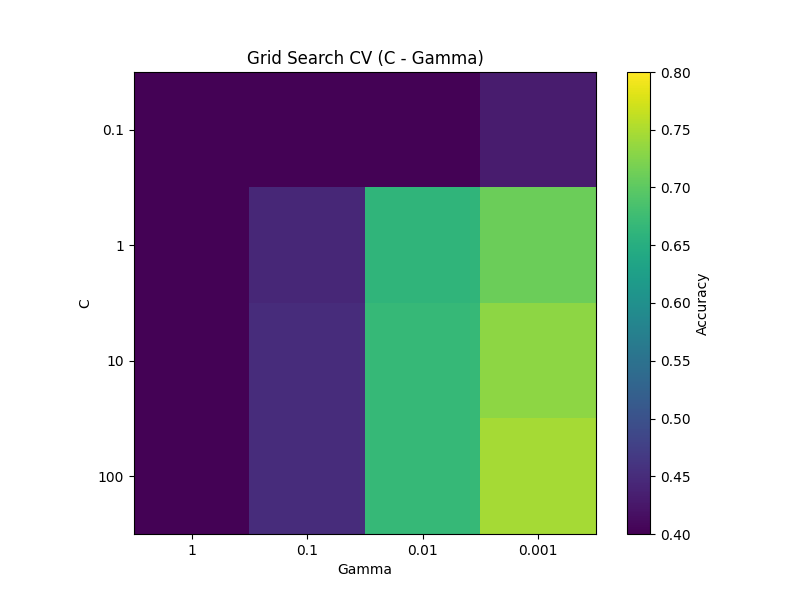
Best parameters: {'C': 100, 'gamma': 0.001}
Test set score: 0.7777777777777778最良なパラメータの組み合わせはbest_params_で取り出すことができます。
GridSearchCVには引数に層化交差検証で5分割、refit(再学習、デフォルトでTrue)はTrueで良いパラメータで再学習するようにしています。また、verbose=1以上でパラメータの進度を表示することもできます。(デフォルト0)
verbose=2の場合のパラメータ探索進度を載せておきます。
Fitting 5 folds for each of 16 candidates, totalling 80 fits
[CV] END .....................................C=0.1, gamma=1; total time= 0.0s
[CV] END .....................................C=0.1, gamma=1; total time= 0.0s
[CV] END .....................................C=0.1, gamma=1; total time= 0.0s
[CV] END .....................................C=0.1, gamma=1; total time= 0.0s
[CV] END .....................................C=0.1, gamma=1; total time= 0.0s
[CV] END ...................................C=0.1, gamma=0.1; total time= 0.0s
[CV] END ...................................C=0.1, gamma=0.1; total time= 0.0s
[CV] END ...................................C=0.1, gamma=0.1; total time= 0.0s
[CV] END ...................................C=0.1, gamma=0.1; total time= 0.0s
[CV] END ...................................C=0.1, gamma=0.1; total time= 0.0s
[CV] END ..................................C=0.1, gamma=0.01; total time= 0.0s
[CV] END ..................................C=0.1, gamma=0.01; total time= 0.0s
[CV] END ..................................C=0.1, gamma=0.01; total time= 0.0s
[CV] END ..................................C=0.1, gamma=0.01; total time= 0.0s
[CV] END ..................................C=0.1, gamma=0.01; total time= 0.0s
[CV] END .................................C=0.1, gamma=0.001; total time= 0.0s
[CV] END .................................C=0.1, gamma=0.001; total time= 0.0s
[CV] END .................................C=0.1, gamma=0.001; total time= 0.0s
[CV] END .................................C=0.1, gamma=0.001; total time= 0.0s
[CV] END .................................C=0.1, gamma=0.001; total time= 0.0s
[CV] END .......................................C=1, gamma=1; total time= 0.0s
[CV] END .......................................C=1, gamma=1; total time= 0.0s
[CV] END .......................................C=1, gamma=1; total time= 0.0s
[CV] END .......................................C=1, gamma=1; total time= 0.0s
[CV] END .......................................C=1, gamma=1; total time= 0.0s
[CV] END .....................................C=1, gamma=0.1; total time= 0.0s
[CV] END .....................................C=1, gamma=0.1; total time= 0.0s
[CV] END .....................................C=1, gamma=0.1; total time= 0.0s
[CV] END .....................................C=1, gamma=0.1; total time= 0.0s
[CV] END .....................................C=1, gamma=0.1; total time= 0.0s
[CV] END ....................................C=1, gamma=0.01; total time= 0.0s
[CV] END ....................................C=1, gamma=0.01; total time= 0.0s
[CV] END ....................................C=1, gamma=0.01; total time= 0.0s
[CV] END ....................................C=1, gamma=0.01; total time= 0.0s
[CV] END ....................................C=1, gamma=0.01; total time= 0.0s
[CV] END ...................................C=1, gamma=0.001; total time= 0.0s
[CV] END ...................................C=1, gamma=0.001; total time= 0.0s
[CV] END ...................................C=1, gamma=0.001; total time= 0.0s
[CV] END ...................................C=1, gamma=0.001; total time= 0.0s
[CV] END ...................................C=1, gamma=0.001; total time= 0.0s
[CV] END ......................................C=10, gamma=1; total time= 0.0s
[CV] END ......................................C=10, gamma=1; total time= 0.0s
[CV] END ......................................C=10, gamma=1; total time= 0.0s
[CV] END ......................................C=10, gamma=1; total time= 0.0s
[CV] END ......................................C=10, gamma=1; total time= 0.0s
[CV] END ....................................C=10, gamma=0.1; total time= 0.0s
[CV] END ....................................C=10, gamma=0.1; total time= 0.0s
[CV] END ....................................C=10, gamma=0.1; total time= 0.0s
[CV] END ....................................C=10, gamma=0.1; total time= 0.0s
[CV] END ....................................C=10, gamma=0.1; total time= 0.0s
[CV] END ...................................C=10, gamma=0.01; total time= 0.0s
[CV] END ...................................C=10, gamma=0.01; total time= 0.0s
[CV] END ...................................C=10, gamma=0.01; total time= 0.0s
[CV] END ...................................C=10, gamma=0.01; total time= 0.0s
[CV] END ...................................C=10, gamma=0.01; total time= 0.0s
[CV] END ..................................C=10, gamma=0.001; total time= 0.0s
[CV] END ..................................C=10, gamma=0.001; total time= 0.0s
[CV] END ..................................C=10, gamma=0.001; total time= 0.0s
[CV] END ..................................C=10, gamma=0.001; total time= 0.0s
[CV] END ..................................C=10, gamma=0.001; total time= 0.0s
[CV] END .....................................C=100, gamma=1; total time= 0.0s
[CV] END .....................................C=100, gamma=1; total time= 0.0s
[CV] END .....................................C=100, gamma=1; total time= 0.0s
[CV] END .....................................C=100, gamma=1; total time= 0.0s
[CV] END .....................................C=100, gamma=1; total time= 0.0s
[CV] END ...................................C=100, gamma=0.1; total time= 0.0s
[CV] END ...................................C=100, gamma=0.1; total time= 0.0s
[CV] END ...................................C=100, gamma=0.1; total time= 0.0s
[CV] END ...................................C=100, gamma=0.1; total time= 0.0s
[CV] END ...................................C=100, gamma=0.1; total time= 0.0s
[CV] END ..................................C=100, gamma=0.01; total time= 0.0s
[CV] END ..................................C=100, gamma=0.01; total time= 0.0s
[CV] END ..................................C=100, gamma=0.01; total time= 0.0s
[CV] END ..................................C=100, gamma=0.01; total time= 0.0s
[CV] END ..................................C=100, gamma=0.01; total time= 0.0s
[CV] END .................................C=100, gamma=0.001; total time= 0.0s
[CV] END .................................C=100, gamma=0.001; total time= 0.0s
[CV] END .................................C=100, gamma=0.001; total time= 0.0s
[CV] END .................................C=100, gamma=0.001; total time= 0.0s
[CV] END .................................C=100, gamma=0.001; total time= 0.0s■Meta Estimator
Meta Estimatorとは、機械学習モデルを他の推定器(アルゴリズム)をラップして追加の処理を行うモデルで、複雑なモデルを構築することができます。
先ほどのGridSearchCVもpredictメソッドやscoreメソッドを呼ぶことができ、機械学習モデルのように振る舞いますが、実際には他の機械学習モデルを最適化するラッパーであり代表的なMeta Estimatorの一つで、実際にガウシアンカーネル法サポートベクターマシンでラップさせました。
他にもPipelineなど色々なことができる画期的なフレームワークなのですが、それはまたの機会に。
■おわりに
Meta Estimatorは多様なモデル(複数のモデルを組み合わせるStackingClassifier等もある)をラップさせながら色々なことができます。
GridSearchCVに関しては単一のデータセットで学習と評価をする際とほとんど同じ行数で汎化性能の高いハイパーパラメータの最適化からモデル構築、評価までできるようになっています。
■参考文献
- Andreas C. Muller, Sarah Guido. Pythonではじめる機械学習. 中田 秀基 訳. オライリー・ジャパン. 2017. 392p.
- ChatGPT. 4o mini. OpenAI. 2024. https://chatgpt.com/
- API Reference. scikit-learn.org. https://scikit-learn.org/stable/api/index.html