AIって結局何なのかよく分からないので、とりあえず100日間勉強してみた Day25
経緯についてはこちらをご参照ください。
■本日の進捗
●交互作用特徴量を理解
■はじめに
引き続き「Pythonではじめる機械学習(オライリー・ジャパン)」で学んでいきます。
特徴量エンジニアリングから交互作用特徴量を学んでいきます。
■交互作用特徴量
まずは前回学んだビニング(binning)の結果を振り返りたいと思います。
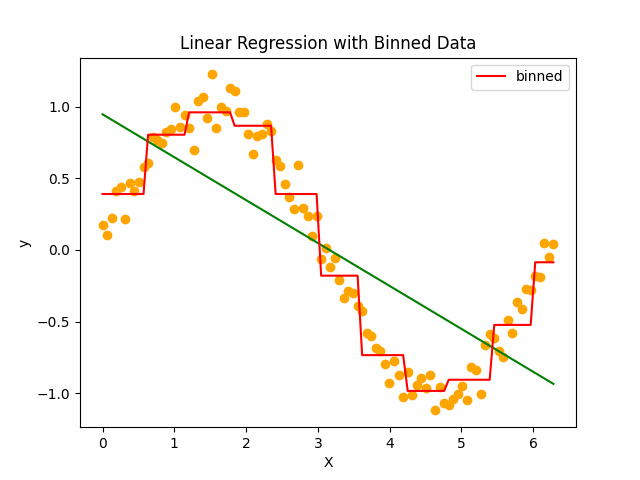
線形モデルでは予測が難しいデータセットに対して、ビニングを適用するだけである程度傾向を捉えることができるようになりました。
しかし個々のビンを見てみると傾きがなく(本来のデータに対して学習したモデルが)情報量が大きく損なわれていることが分かります。できればこの情報量も捨てることなく予測できる学習モデルを構築したいです。
そんな時に実用的な手法が交互作用特徴量(interaction features)です。元のデータから特徴量を組み合わせて新たな特徴量を生成する手法で、モデルの予測精度を向上させることができます。
新しい特徴量を生成する方法にはいくつか種類があり、まずはシンプルに足し合わせる加算的交互作用特徴量でその挙動を見てみます。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import OneHotEncoder
np.random.seed(0)
X = np.linspace(0, 2 * np.pi, 100).reshape(-1, 1)
y = np.sin(X) + np.random.normal(scale=0.1, size=X.shape)
bins = np.linspace(0, 6, 11)
which_bin = np.digitize(X, bins=bins)
encoder = OneHotEncoder(sparse_output=False)
X_binned = encoder.fit_transform(which_bin)
model_binned = LinearRegression()
model_binned.fit(X_binned, y)
y_binned_pred = model_binned.predict(X_binned)
model = LinearRegression()
model.fit(X, y)
y_pred = model.predict(X)
plt.plot(X, y_binned_pred, color='red', label='binned')
X_interaction = X_binned + X
X_combined = np.hstack((X_binned, X_interaction))
model_binned = LinearRegression()
model_binned.fit(X_combined, y)
y_interaction_pred = model_binned.predict(X_combined)
model = LinearRegression()
model.fit(X, y)
y_pred = model.predict(X)
plt.scatter(X, y, color='orange')
plt.plot(X, y_pred, color='green')
plt.plot(X, y_interaction_pred, color='blue', label='interaction')
plt.legend()
plt.xlabel('X')
plt.ylabel('y')
plt.title('Binned Linear Regression with Interaction Features')
plt.show()
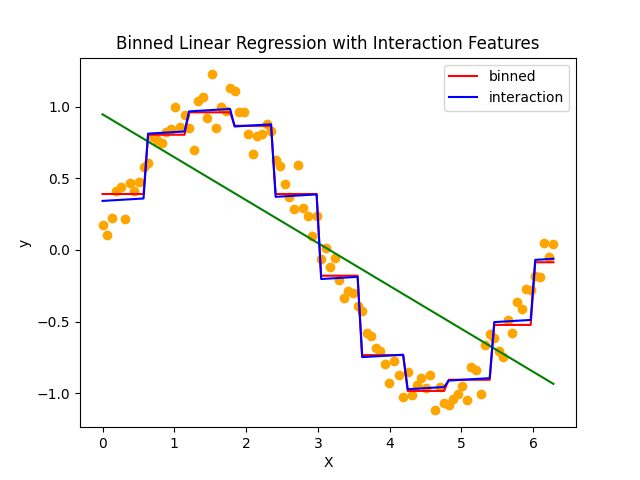
加法的交互作用は特徴量の和を追加しています。ビニングを適用した線形回帰モデルに比べて、個々のビンに傾きの情報が追加されていることが分かります。
個々のビンに対する影響が独立して加算されるので、傾きは常に一定で、線形性を強調することはできるものの、このような複雑なデータに対してはあまり有効ではなさそうです。
他にも特徴量の積を追加する乗法的交互作用特徴量もあり、これは掛け合わせる特徴量同士の相互作用を捉えることができるため、非線形性を学習することが可能になります。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import OneHotEncoder
np.random.seed(0)
X = np.linspace(0, 2 * np.pi, 100).reshape(-1, 1)
y = np.sin(X) + np.random.normal(scale=0.1, size=X.shape)
bins = np.linspace(0, 6, 11)
which_bin = np.digitize(X, bins=bins)
encoder = OneHotEncoder(sparse_output=False)
X_binned = encoder.fit_transform(which_bin)
model_binned = LinearRegression()
model_binned.fit(X_binned, y)
y_binned_pred = model_binned.predict(X_binned)
model = LinearRegression()
model.fit(X, y)
y_pred = model.predict(X)
plt.plot(X, y_binned_pred, color='red', label='binned')
X_interaction = X_binned * X
X_combined = np.hstack((X_binned, X_interaction))
model_binned = LinearRegression()
model_binned.fit(X_combined, y)
y_interaction_pred = model_binned.predict(X_combined)
model = LinearRegression()
model.fit(X, y)
y_pred = model.predict(X)
plt.scatter(X, y, color='orange')
plt.plot(X, y_pred, color='green')
plt.plot(X, y_interaction_pred, color='blue', label='interaction')
plt.legend()
plt.xlabel('X')
plt.ylabel('y')
plt.title('Binned Linear Regression with Interaction Features')
plt.show()
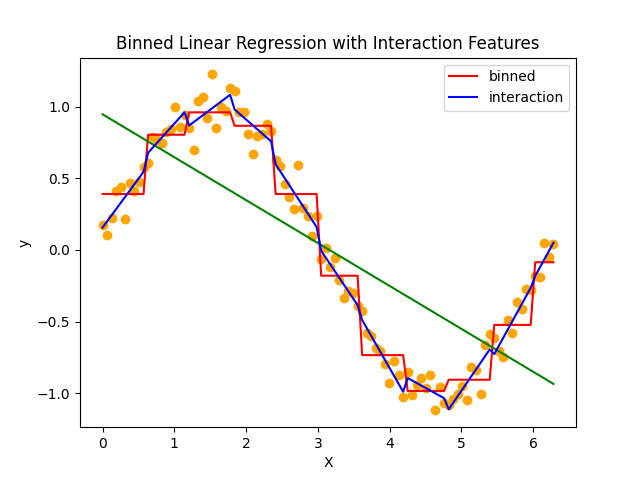
個々のビンがオフセットと傾きを持つようになり、元データを良く再現できるようになっています。
一部過剰適合気味な部分が見受けられるのですが、これは元のビニングの粒度を変えれば複雑度を落とすことができます。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import OneHotEncoder
np.random.seed(0)
X = np.linspace(0, 2 * np.pi, 100).reshape(-1, 1)
y = np.sin(X) + np.random.normal(scale=0.1, size=X.shape)
bins = np.linspace(0, 6, 7)
which_bin = np.digitize(X, bins=bins)
encoder = OneHotEncoder(sparse_output=False)
X_binned = encoder.fit_transform(which_bin)
model_binned = LinearRegression()
model_binned.fit(X_binned, y)
y_binned_pred = model_binned.predict(X_binned)
model = LinearRegression()
model.fit(X, y)
y_pred = model.predict(X)
plt.plot(X, y_binned_pred, color='red', label='binned')
X_interaction = X_binned * X
X_combined = np.hstack((X_binned, X_interaction))
model_binned = LinearRegression()
model_binned.fit(X_combined, y)
y_interaction_pred = model_binned.predict(X_combined)
model = LinearRegression()
model.fit(X, y)
y_pred = model.predict(X)
plt.scatter(X, y, color='orange')
plt.plot(X, y_pred, color='green')
plt.plot(X, y_interaction_pred, color='blue', label='interaction')
plt.legend()
plt.xlabel('X')
plt.ylabel('y')
plt.title('Binned Linear Regression with Interaction Features')
plt.show()
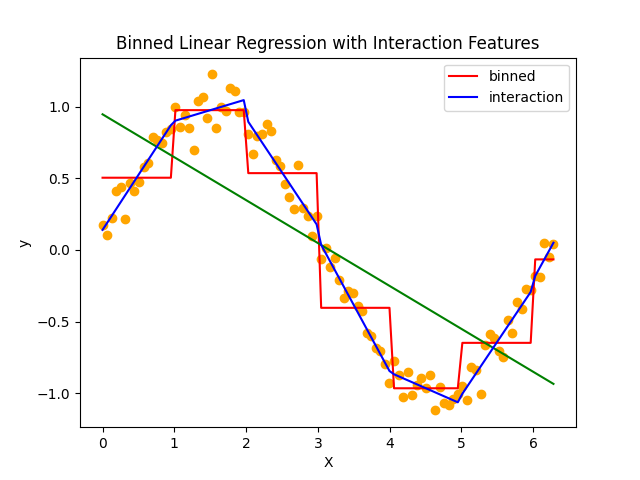
ビニング後の学習モデルの予測精度は微妙になってしまいますが、交互作用特徴量を加えるとかなり上手く元データに近い予測ができるように学習できています。
■おわりに
これまで学んできたワンホットエンコーディング、ビニングに交互作用特徴量を追加して線形回帰を見事にsin波に適用することができました。
機械学習アルゴリズム自体を一切調整することなく、実質的にデータを増やすこともなく、これだけ合わせ込むことができたのは特徴量エンジニアリングの成せる技なのかなと思いました。
■参考文献
- Andreas C. Muller, Sarah Guido. Pythonではじめる機械学習. 中田 秀基 訳. オライリー・ジャパン. 2017. 392p.
- ChatGPT. 4o mini. OpenAI. 2024. https://chatgpt.com/
- API Reference. scikit-learn.org. https://scikit-learn.org/stable/api/index.html