AIって結局何なのかよく分からないので、とりあえず100日間勉強してみた Day22
経緯についてはこちらをご参照ください。
■本日の進捗
●DBSCANを理解
■はじめに
引き続き「Pythonではじめる機械学習(オライリー・ジャパン)」で学んでいきます。
今回もクラスタリング手法の一種である密度に基づくクラスタリング手法、DBSCANを触っていきます。
■DBSCAN
DBSCAN(density-based spatial clustering of applications with noise:密度に基づくノイズあり空間クラスタリング)とは、特徴空間で多くのデータポイントが密集している領域(dense:高密度領域)に属する点を見つけ、クラスタとは高密度領域であり、クラスタとクラスタの間には空虚な領域で区切られているだろうという考え方でクラスタリングを行う手法です。
計算コストはこれまでのk-meansや凝集型クラスタリングよりも高いものの、ノイズを含むような複雑で大きいデータセットにも適用可能です。
クラスタを形成するためのデータポイント間の最大距離(近傍半径)を決めるパラメータε(eps)と、1つのクラスタに必要な最小データポイント数を決めるパラメータmin_samplesを設定可能で、εの範囲にあるデータポイントはすべて同一のクラスタに割り当てられ、min_samples数以上データポイントがεの範囲内にあるデータポイントはコアサンプル(あるいはコアポイント)と呼ばれます。
min_samples未満のデータポイントしかない場合には境界点とされ、どのクラスタにも属さない点は外れ値として扱われます。
クラスタ数を事前に設定する必要がなく、ノイズにも耐性がある他、不均一な形、サイズのクラスタを検出することが可能になっています。その代わりパラメータの設定に大きく影響を受け、高次元データセットに対しては次元の呪いを受けやすくなります。
いつも通りあやめデータセットに適用してその効果を見てみましょう。
from sklearn.cluster import DBSCAN
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
import numpy as np
iris = load_iris()
X = iris.data
dbscan = DBSCAN(eps=0.5, min_samples=5)
labels = dbscan.fit_predict(X)
unique_labels = np.unique(labels)
for label in unique_labels:
if label == -1:
plt.scatter(X[labels == label, 0], X[labels == label, 1], label='Noise', color='black', marker='x')
else:
plt.scatter(X[labels == label, 0], X[labels == label, 1], label=f'Cluster {label}')
plt.title('DBSCAN')
plt.xlabel('Sepal Length')
plt.ylabel('Sepal Width')
plt.legend()
plt.show()
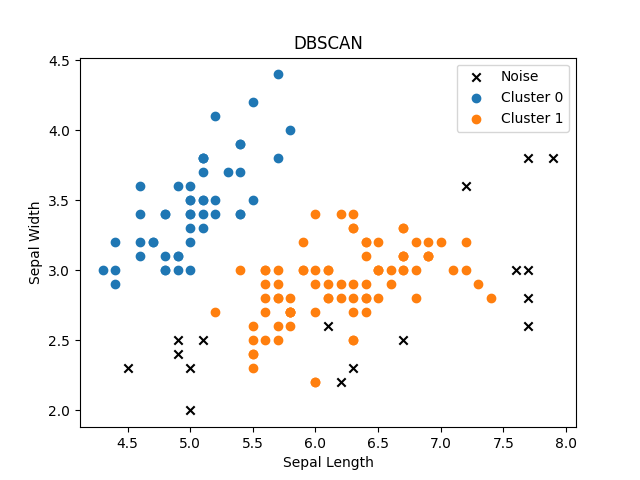
高密度領域から外れたデータポイントはその多くが外れ値として認識されています。
まずはεを振ってみて、その挙動を見てみます。
from sklearn.cluster import DBSCAN
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
import numpy as np
iris = load_iris()
X = iris.data
fig, axes = plt.subplots(2, 5, figsize=(20, 8))
axes = axes.flatten()
eps_values = np.arange(0.1, 1.1, 0.1)
for i, eps in enumerate(eps_values):
dbscan = DBSCAN(eps=eps, min_samples=5)
labels = dbscan.fit_predict(X)
unique_labels = np.unique(labels)
for label in unique_labels:
if label == -1:
axes[i].scatter(X[labels == label, 0], X[labels == label, 1], label='Noise', color='black', marker='x')
else:
axes[i].scatter(X[labels == label, 0], X[labels == label, 1], label=f'Cluster {label}')
axes[i].set_title(f'eps={eps:.1f}')
axes[i].set_xlabel('Sepal Length')
axes[i].set_ylabel('Sepal Width')
plt.tight_layout()
plt.show()
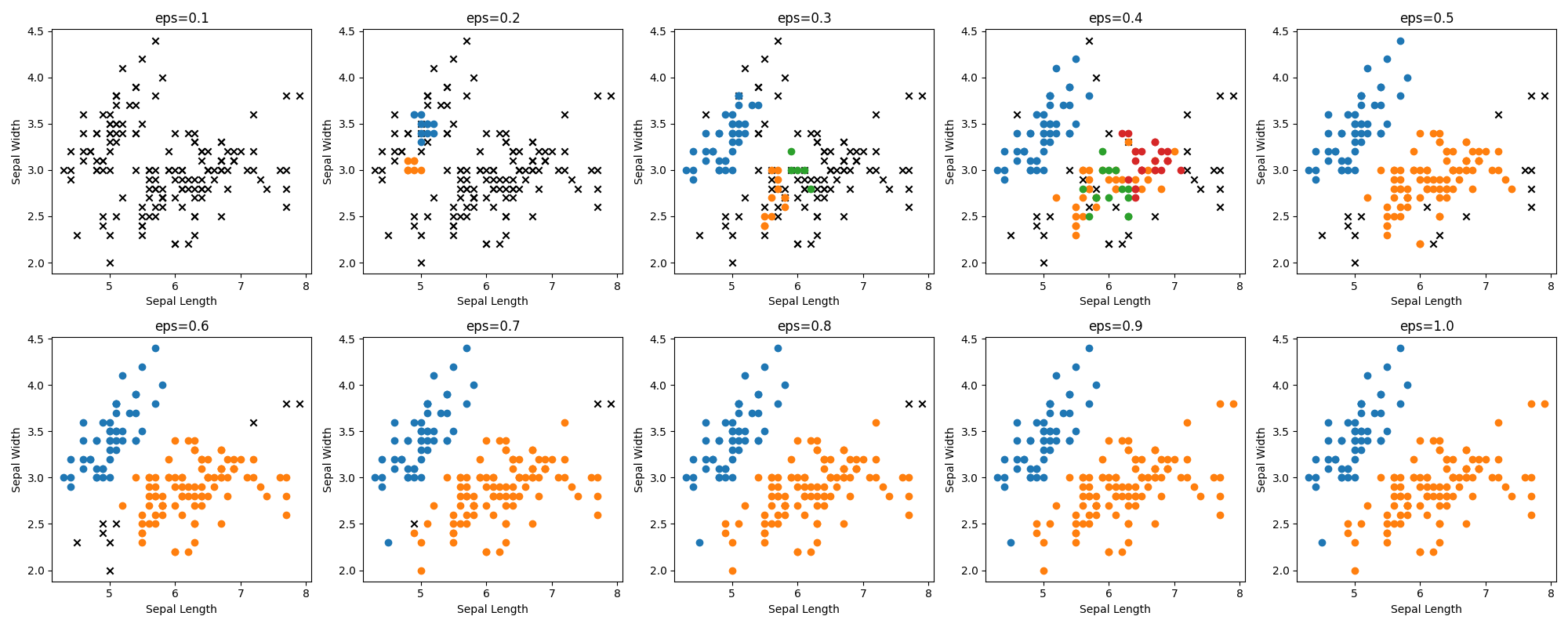
εの値が低いと多くのデータセットを外れ値として認識してしまっています。また0.5を過ぎたあたりからクラスタの数が2つになってしまっています。恐らくこの辺りが適切な最大距離なのでしょう。
同様にεを0.4に固定して、min_samplesを1から10まで振ってみましょう。
from sklearn.cluster import DBSCAN
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
import numpy as np
iris = load_iris()
X = iris.data
fig, axes = plt.subplots(2, 5, figsize=(20, 8))
axes = axes.flatten()
min_samples_values = np.arange(1, 11)
for i, min_samples in enumerate(min_samples_values):
dbscan = DBSCAN(eps=0.4, min_samples=min_samples)
labels = dbscan.fit_predict(X)
unique_labels = np.unique(labels)
for label in unique_labels:
if label == -1:
axes[i].scatter(X[labels == label, 0], X[labels == label, 1], label='Noise', color='black', marker='x')
else:
axes[i].scatter(X[labels == label, 0], X[labels == label, 1], label=f'Cluster {label}')
axes[i].set_title(f'min_samples={min_samples}')
axes[i].set_xlabel('Sepal Length')
axes[i].set_ylabel('Sepal Width')
plt.tight_layout()
plt.show()
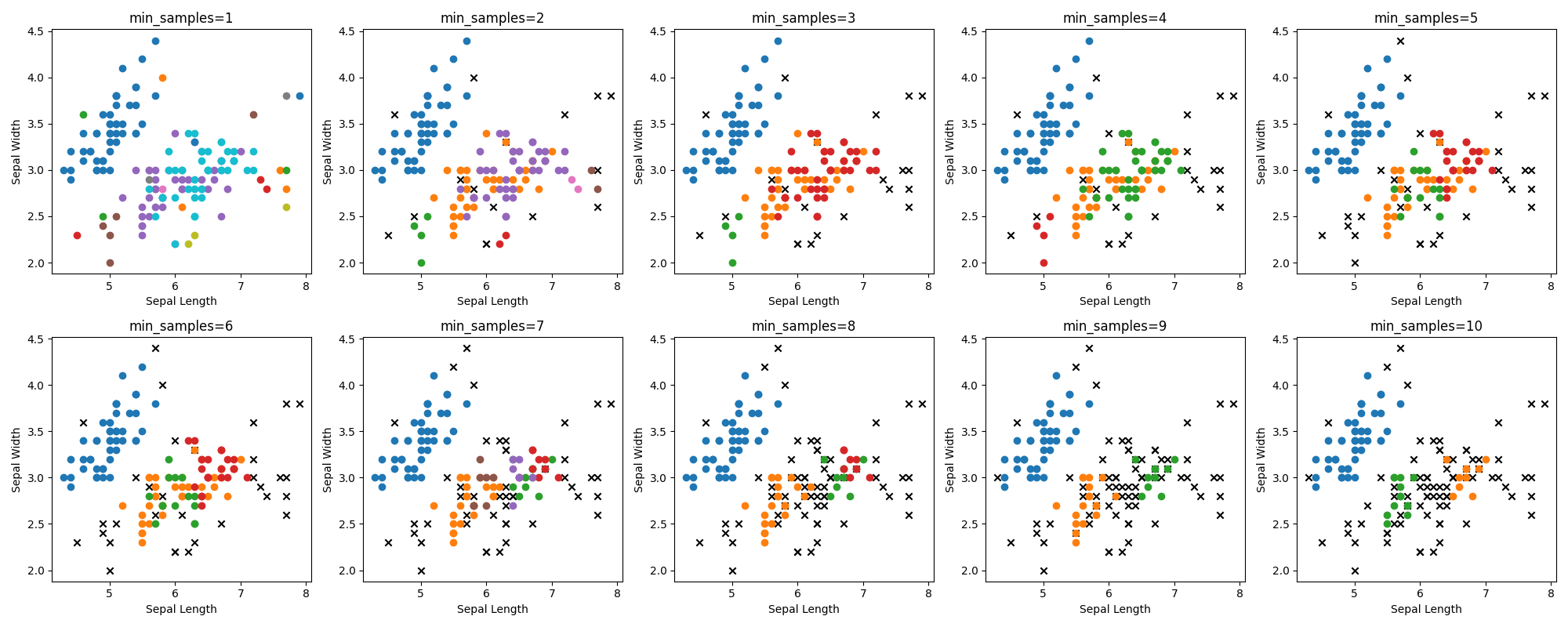
クラスタリングをするには難易度の高い分布をしているデータセットですが、なんとか?3つのクラスタに分離できたみたいです。
最後に凝集型クラスタリングで分離したmake_circlesデータセットでDBSCANを適用してみたいと思います。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_circles
from sklearn.cluster import DBSCAN
from sklearn.metrics import silhouette_score
X, y = make_circles(n_samples=1000, noise=0.1, factor=0.5, random_state=8)
dbscan = DBSCAN(eps=0.1, min_samples=6)
dbscan.fit(X)
labels = dbscan.labels_
plt.figure(figsize=(10, 6))
plt.scatter(X[:, 0], X[:, 1], c=labels, cmap=plt.cm.get_cmap('hsv', len(np.unique(labels))), edgecolors='k', s=50)
if -1 in labels:
plt.scatter(X[labels == -1, 0], X[labels == -1, 1], c='black', marker='x', s=100, label='Noise')
plt.title('DBSCAN')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.grid()
plt.tight_layout()
plt.show()
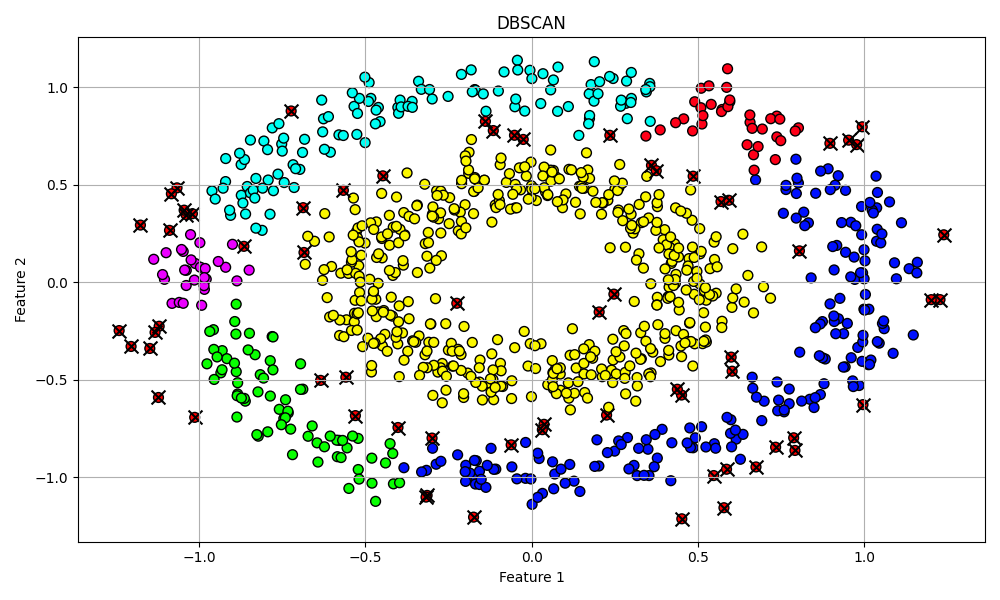
εとmin_samplesは少し弄っています。DBSCANはこのような複雑な(非線形な)データセットに対してもクラスタ間の距離が明確で間に空虚な領域があるようなものには上手くクラスタリングできていることが分かりました。
■おわりに
DBSCANのハイパーパラメータを弄ってシンプルな(かつクラスタリングするのが難しい)データセットに対する挙動を見てみました。その挙動は比較的直観的で分かりやすいですが、最適化するにはなかなか難しいなと感じました。ただ、非線形データセットに対しても適用できることが理解できたので使いこなせれば良いツールになるのでしょう。
また、ノイズがない(今回はほとんど綺麗なデータセットだったので特に)データセットに対しては「おいおい、何してるんだよ」と思いたくなるくらい外れ値をバンバン抽出してくれていましたが、現実のデータではそこそこの量の外れ値があることを想定すると、これもまたDBSCANの大きなメリットに思えます。
■参考文献
- Andreas C. Muller, Sarah Guido. Pythonではじめる機械学習. 中田 秀基 訳. オライリー・ジャパン. 2017. 392p.
- ChatGPT. 4o mini. OpenAI. 2024. https://chatgpt.com/
- API Reference. scikit-learn.org. https://scikit-learn.org/stable/api/index.html