AIって結局何なのかよく分からないので、とりあえず100日間勉強してみた Day100
経緯についてはこちらをご参照ください。
■本日の進捗
- Attention Mechanismの理解
■はじめに
今回も「ゼロから作るDeep Learning② 自然言語処理編(オライリー・ジャパン)」から学んでいきます。
今回は、seq2seqモデルの性能を向上させるためにAttention Mechanismを学びます。
■Attention Mechanism
Attention Mechanism(注意機構)とは、Encoderが生成する隠れ状態に基づいて、Decoderが必要とする情報に注意を向ける機構のことです。
■Attention Encoder
Attention MechanismではDecoderが生成する出力に対してEncoderの隠れ状態全体からどのタイムステップが重要かを学習し、動的に重み付けを行います。
そのためにまずはEncoderからDecoderに渡す隠れ状態を最終状態だけでなく、全ての隠れ状態を使用できるようにします。(これはこれまで実装したEncoderクラスを継承しています。)
class AttentionEncoder(Encoder):
def forward(self, xs):
xs = self.embed.forward(xs)
hs = self.lstm.forward(xs)
return hs
def backward(self, dhs):
dout = self.lstm.backward(dhs)
dout = self.embed.backward(dout)
return dout
■重み付き和
Attention Encoderの出力する全ての隠れ状態から、必要な情報のみに注意を向けるようにしてからDecoderの処理に移行します。
ここで、モデルが学習できるようになるためには、誤差逆伝播法を適用(微分可能)できる必要があります。ここでは重みを導入して注意を向けるべき情報に重みを付けます。すなわち、重み付き和を計算するために下記のクラスを用意しておきます。
初期化においてはself.params, self.gradsは使いませんが、空のリストとします。
class WeightSum:
def __init__(self):
self.params, self.grads = [], []
self.cache = None
順伝播においては、Encoderの出力(hs)と重み(a)を受け取り、加重平均を計算します。ここでは、重みをバッチサイズ(N)、タイムステップ(T)、1の形状に整形した重み(ar)を用意して、隠れ状態と掛けあわせて、時系列方向に加重平均(c)を計算します。ここではNumPyのブロードキャストを使用しています。
def forward(self, hs, a):
N, T, H = hs.shape
ar = a.reshape(N, T, 1)
t = hs * ar
c = np.sum(t, axis=1)
self.cache = (hs, ar)
return c
逆伝播では加重平均の結果に対する勾配(dc)を受け取り、元の隠れ状態(hs)と重み(a)に対する勾配を計算します。ここで、dtは勾配(dc)を時系列方向(T)に繰り返し、(N, T, H)の形状になるようにしています。
def backward(self, dc):
hs, ar = self.cache
N, T, H = hs.shape
dt = dc.reshape(N, 1, H).repeat(T, axis=1)
dar = dt * hs
dhs = dt * ar
da = np.sum(dar, axis=2)
return dhs, da
■Attention重み
上記の重み付き和を計算するためのAttentionの重みを自動的に設定できるよう、学習できる形で容易します。ここでは類似度(内積)から重要度を推定し、いつものようにSoftmaxで正規化します。
重み付き和と同様に初期化します。
class AttentionWeight:
def __init__(self):
self.params, self.grads = [], []
self.softmax = Softmax()
self.cache = None
順伝播では、全ての隠れ状態(hs)と現在の隠れ状態(h)を受け取り、内積を計算できる形(hr)に整形してから内積を取り、時間方向に加算(s)します。Softmaxを適用して確率分布にしたものがAttentionの重み(a)です。
def forward(self, hs, h):
N, T, H = hs.shape
hr = h.reshape(N, 1, H)#.repeat(T, axis=1)
t = hs * hr
s = np.sum(t, axis=2)
a = self.softmax.forward(s)
self.cache = (hs, hr)
return a
逆伝播では、Attentionの重みの勾配(da)を受け取り、Softmaxの勾配(ds)、その次元調整(dt)、隠れ状態に対する勾配(dhs)、整形した隠れ状態に対する勾配(dhr)、これを時系列方向(T)に和を取った元の隠れ状態に対する勾配(dh)を計算していきます。
def backward(self, da):
hs, hr = self.cache
N, T, H = hs.shape
ds = self.softmax.backward(da)
dt = ds.reshape(N, T, 1).repeat(H, axis=2)
dhs = dt * hr
dhr = dt * hs
dh = np.sum(dhr, axis=1)
return dhs, dh
■Attention
以上のAttentionの重み計算と、その重みを用いた重み付き和の計算を備えたAttention Mechanismの中枢の担うクラスを用意します。
ここまで学んできたように、全ての隠れ状態であるEncoderの出力に対して、注意を向けて各単語の重みを計算し、隠れ状態と重みの重み付き和からコンテキストベクトルを出力するための機構です。
class Attention:
def __init__(self):
self.params, self.grads = [], []
self.attention_weight_layer = AttentionWeight()
self.weight_sum_layer = WeightSum()
self.attention_weight = None
def forward(self, hs, h):
a = self.attention_weight_layer.forward(hs, h)
out = self.weight_sum_layer.forward(hs, a)
self.attention_weight = a
return out
def backward(self, dout):
dhs0, da = self.weight_sum_layer.backward(dout)
dhs1, dh = self.attention_weight_layer.backward(da)
dhs = dhs0 + dhs1
return dhs, dh
■時系列Attention
Attention Mechanismを時系列データに対応させるために、複数のAttention層を追加するようにします。
まずは、これまでと同様に初期化します。ここでは、各タイムステップでのAttention層とAttentionの重みを初期化しています。
class TimeAttention:
def __init__(self):
self.params, self.grads = [], []
self.layers = None
self.attention_weights = None
順伝播では、Encoderからの隠れ状態(hs_enc)とDecoderからの隠れ状態(hs_dec)を受け取ります。Attention層のインスタンスを生成したら、Attentionを実行し層をリストに追加、結果として得られたAttention重みを保持することを、タイムステップ分繰り返します。
def forward(self, hs_enc, hs_dec):
N, T, H = hs_dec.shape
out = np.empty_like(hs_dec)
self.layers = []
self.attention_weights = []
for t in range(T):
layer = Attention()
out[:, t, :] = layer.forward(hs_enc, hs_dec[:,t,:])
self.layers.append(layer)
self.attention_weights.append(layer.attention_weight)
return out
逆伝播では、順伝播の出力に対する損失の勾配を受け取り、リストに追加しておいたAttention層の逆伝播を同様にタイムステップ分行って、Encoderの隠れ状態に対する勾配(dhs)、Decoderの時刻(t)での隠れ状態に対する勾配を求めます。
def backward(self, dout):
N, T, H = dout.shape
dhs_enc = 0
dhs_dec = np.empty_like(dout)
for t in range(T):
layer = self.layers[t]
dhs, dh = layer.backward(dout[:, t, :])
dhs_enc += dhs
dhs_dec[:,t,:] = dh
return dhs_enc, dhs_dec
■Attention Decoder
Encoderの場合と同様に、Attention Mechanismで用いるDecoderを用意します。しかしAttentionが追加されただけで、これまでのDecoderとそれほど違いはありません。
class AttentionDecoder:
def __init__(self, vocab_size, wordvec_size, hidden_size):
V, D, H = vocab_size, wordvec_size, hidden_size
rn = np.random.randn
embed_W = (rn(V, D) / 100).astype('f')
lstm_Wx = (rn(D, 4 * H) / np.sqrt(D)).astype('f')
lstm_Wh = (rn(H, 4 * H) / np.sqrt(H)).astype('f')
lstm_b = np.zeros(4 * H).astype('f')
affine_W = (rn(2*H, V) / np.sqrt(2*H)).astype('f')
affine_b = np.zeros(V).astype('f')
self.embed = TimeEmbedding(embed_W)
self.lstm = TimeLSTM(lstm_Wx, lstm_Wh, lstm_b, stateful=True)
self.attention = TimeAttention()
self.affine = TimeAffine(affine_W, affine_b)
layers = [self.embed, self.lstm, self.attention, self.affine]
self.params, self.grads = [], []
for layer in layers:
self.params += layer.params
self.grads += layer.grads
def forward(self, xs, enc_hs):
h = enc_hs[:,-1]
self.lstm.set_state(h)
out = self.embed.forward(xs)
dec_hs = self.lstm.forward(out)
c = self.attention.forward(enc_hs, dec_hs)
out = np.concatenate((c, dec_hs), axis=2)
score = self.affine.forward(out)
return score
def backward(self, dscore):
dout = self.affine.backward(dscore)
N, T, H2 = dout.shape
H = H2 // 2
dc, ddec_hs0 = dout[:,:,:H], dout[:,:,H:]
denc_hs, ddec_hs1 = self.attention.backward(dc)
ddec_hs = ddec_hs0 + ddec_hs1
dout = self.lstm.backward(ddec_hs)
dh = self.lstm.dh
denc_hs[:, -1] += dh
self.embed.backward(dout)
return denc_hs
def generate(self, enc_hs, start_id, sample_size):
sampled = []
sample_id = start_id
h = enc_hs[:, -1]
self.lstm.set_state(h)
for _ in range(sample_size):
x = np.array([sample_id]).reshape((1, 1))
out = self.embed.forward(x)
dec_hs = self.lstm.forward(out)
c = self.attention.forward(enc_hs, dec_hs)
out = np.concatenate((c, dec_hs), axis=2)
score = self.affine.forward(out)
sample_id = np.argmax(score.flatten())
sampled.append(sample_id)
return sampled
■Attention seq2seq
seq2seqに関しても上記の層を使うように変更します。これまでのseq2seqクラスを継承して、EncoderをAttention Encoderに、DecoderをAttention Decoderに変えるだけです。
class AttentionSeq2seq(Seq2seq):
def __init__(self, vocab_size, wordvec_size, hidden_size):
args = vocab_size, wordvec_size, hidden_size
self.encoder = AttentionEncoder(*args)
self.decoder = AttentionDecoder(*args)
self.softmax = TimeSoftmaxWithLoss()
self.params = self.encoder.params + self.decoder.params
self.grads = self.encoder.grads + self.decoder.grads
■Attention Mechanismの学習
seq2seq(Encoder-Decoder)モデルで用いた(可変長の時系列データとしての)簡単な足し算の学習をAttention Mechanismにも行ってみます。
import sys
import os
sys.path.append('..')
import numpy as np
import matplotlib.pyplot as plt
import pickle
from sklearn.utils.extmath import randomized_svd
import collections
from Encoder_Decoder_class import *
import sequence
class Softmax:
def __init__(self):
self.params, self.grads = [], []
self.out = None
def forward(self, x):
self.out = softmax(x)
return self.out
def backward(self, dout):
dx = self.out * dout
sumdx = np.sum(dx, axis=1, keepdims=True)
dx -= self.out * sumdx
return dx
class WeightSum:
def __init__(self):
self.params, self.grads = [], []
self.cache = None
def forward(self, hs, a):
N, T, H = hs.shape
ar = a.reshape(N, T, 1)#.repeat(T, axis=1)
t = hs * ar
c = np.sum(t, axis=1)
self.cache = (hs, ar)
return c
def backward(self, dc):
hs, ar = self.cache
N, T, H = hs.shape
dt = dc.reshape(N, 1, H).repeat(T, axis=1)
dar = dt * hs
dhs = dt * ar
da = np.sum(dar, axis=2)
return dhs, da
class AttentionWeight:
def __init__(self):
self.params, self.grads = [], []
self.softmax = Softmax()
self.cache = None
def forward(self, hs, h):
N, T, H = hs.shape
hr = h.reshape(N, 1, H)#.repeat(T, axis=1)
t = hs * hr
s = np.sum(t, axis=2)
a = self.softmax.forward(s)
self.cache = (hs, hr)
return a
def backward(self, da):
hs, hr = self.cache
N, T, H = hs.shape
ds = self.softmax.backward(da)
dt = ds.reshape(N, T, 1).repeat(H, axis=2)
dhs = dt * hr
dhr = dt * hs
dh = np.sum(dhr, axis=1)
return dhs, dh
class Attention:
def __init__(self):
self.params, self.grads = [], []
self.attention_weight_layer = AttentionWeight()
self.weight_sum_layer = WeightSum()
self.attention_weight = None
def forward(self, hs, h):
a = self.attention_weight_layer.forward(hs, h)
out = self.weight_sum_layer.forward(hs, a)
self.attention_weight = a
return out
def backward(self, dout):
dhs0, da = self.weight_sum_layer.backward(dout)
dhs1, dh = self.attention_weight_layer.backward(da)
dhs = dhs0 + dhs1
return dhs, dh
class TimeAttention:
def __init__(self):
self.params, self.grads = [], []
self.layers = None
self.attention_weights = None
def forward(self, hs_enc, hs_dec):
N, T, H = hs_dec.shape
out = np.empty_like(hs_dec)
self.layers = []
self.attention_weights = []
for t in range(T):
layer = Attention()
out[:, t, :] = layer.forward(hs_enc, hs_dec[:,t,:])
self.layers.append(layer)
self.attention_weights.append(layer.attention_weight)
return out
def backward(self, dout):
N, T, H = dout.shape
dhs_enc = 0
dhs_dec = np.empty_like(dout)
for t in range(T):
layer = self.layers[t]
dhs, dh = layer.backward(dout[:, t, :])
dhs_enc += dhs
dhs_dec[:,t,:] = dh
return dhs_enc, dhs_dec
class AttentionEncoder(Encoder):
def forward(self, xs):
xs = self.embed.forward(xs)
hs = self.lstm.forward(xs)
return hs
def backward(self, dhs):
dout = self.lstm.backward(dhs)
dout = self.embed.backward(dout)
return dout
class AttentionDecoder:
def __init__(self, vocab_size, wordvec_size, hidden_size):
V, D, H = vocab_size, wordvec_size, hidden_size
rn = np.random.randn
embed_W = (rn(V, D) / 100).astype('f')
lstm_Wx = (rn(D, 4 * H) / np.sqrt(D)).astype('f')
lstm_Wh = (rn(H, 4 * H) / np.sqrt(H)).astype('f')
lstm_b = np.zeros(4 * H).astype('f')
affine_W = (rn(2*H, V) / np.sqrt(2*H)).astype('f')
affine_b = np.zeros(V).astype('f')
self.embed = TimeEmbedding(embed_W)
self.lstm = TimeLSTM(lstm_Wx, lstm_Wh, lstm_b, stateful=True)
self.attention = TimeAttention()
self.affine = TimeAffine(affine_W, affine_b)
layers = [self.embed, self.lstm, self.attention, self.affine]
self.params, self.grads = [], []
for layer in layers:
self.params += layer.params
self.grads += layer.grads
def forward(self, xs, enc_hs):
h = enc_hs[:,-1]
self.lstm.set_state(h)
out = self.embed.forward(xs)
dec_hs = self.lstm.forward(out)
c = self.attention.forward(enc_hs, dec_hs)
out = np.concatenate((c, dec_hs), axis=2)
score = self.affine.forward(out)
return score
def backward(self, dscore):
dout = self.affine.backward(dscore)
N, T, H2 = dout.shape
H = H2 // 2
dc, ddec_hs0 = dout[:,:,:H], dout[:,:,H:]
denc_hs, ddec_hs1 = self.attention.backward(dc)
ddec_hs = ddec_hs0 + ddec_hs1
dout = self.lstm.backward(ddec_hs)
dh = self.lstm.dh
denc_hs[:, -1] += dh
self.embed.backward(dout)
return denc_hs
def generate(self, enc_hs, start_id, sample_size):
sampled = []
sample_id = start_id
h = enc_hs[:, -1]
self.lstm.set_state(h)
for _ in range(sample_size):
x = np.array([sample_id]).reshape((1, 1))
out = self.embed.forward(x)
dec_hs = self.lstm.forward(out)
c = self.attention.forward(enc_hs, dec_hs)
out = np.concatenate((c, dec_hs), axis=2)
score = self.affine.forward(out)
sample_id = np.argmax(score.flatten())
sampled.append(sample_id)
return sampled
class AttentionSeq2seq(Seq2seq):
def __init__(self, vocab_size, wordvec_size, hidden_size):
args = vocab_size, wordvec_size, hidden_size
self.encoder = AttentionEncoder(*args)
self.decoder = AttentionDecoder(*args)
self.softmax = TimeSoftmaxWithLoss()
self.params = self.encoder.params + self.decoder.params
self.grads = self.encoder.grads + self.decoder.grads
(x_train, t_train), (x_test, t_test) = sequence.load_data('addition.txt')
char_to_id, id_to_char = sequence.get_vocab()
x_train, x_test = x_train[:, ::-1], x_test[:, ::-1]
vocab_size = len(char_to_id)
wordvec_size = 16
hidden_size = 128
batch_size = 128
max_epoch = 25
max_grad = 5.0
model = AttentionSeq2seq(vocab_size, wordvec_size, hidden_size)
# model = Seq2seq(vocab_size, wordvec_size, hidden_size)
# model = PeekySeq2seq(vocab_size, wordvec_size, hidden_size)
optimizer = Adam()
trainer = Trainer(model, optimizer)
acc_list = []
for epoch in range(max_epoch):
trainer.fit(x_train, t_train, max_epoch=1,
batch_size=batch_size, max_grad=max_grad)
correct_num = 0
for i in range(len(x_test)):
question, correct = x_test[[i]], t_test[[i]]
verbose = i < 10
correct_num += eval_seq2seq(model, question, correct,
id_to_char, verbose, is_reverse=True)
acc = float(correct_num) / len(x_test)
acc_list.append(acc)
print('val acc %.3f%%' % (acc * 100))
x = np.arange(len(acc_list))
plt.plot(x, acc_list, marker='o')
plt.xlabel('epochs')
plt.ylabel('accuracy')
plt.ylim(-0.05, 1.05)
plt.show()
Q 77+85
T 162
O 162
---
Q 975+164
T 1139
O 1139
---
Q 582+84
T 666
O 666
---
Q 8+155
T 163
O 163
---
Q 367+55
T 422
O 422
---
Q 600+257
T 857
O 857
---
Q 761+292
T 1053
O 1053
---
Q 830+597
T 1427
O 1427
---
Q 26+838
T 864
O 864
---
Q 143+93
T 236
O 236
---
val acc 88.760%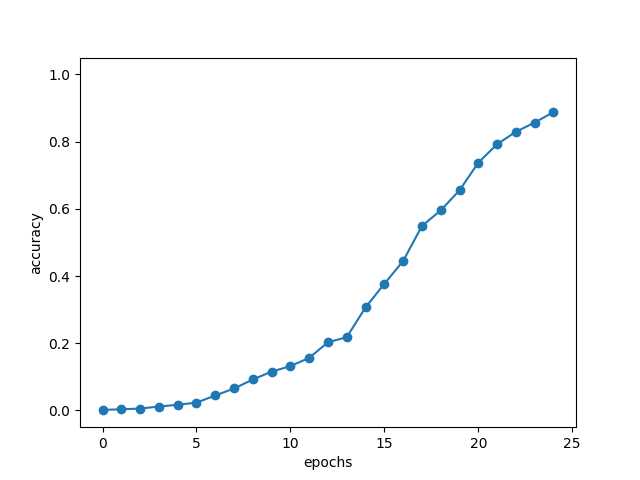
おわりに
今日で100日間機械学習に関する勉強を続けてこれました。
Pythonとは?NumPyとは?という所から始めた訳ですが、最終稿はついにAttention Mechanismについて学ぶことができました。
Attention Mechanismと言えば、機械学習専門ではない自分でも知っているかの有名な論文「Attention Is All You Need」でも出てくる現代の生成AIに関するブレイクスルーを実現したコア技術のひとつです。GPTのような文章生成AIだけでなく、画像生成においてもコンテキストと画像を結びつける技術においてStable Fusionなどの画像生成AIでも用いられている革新的な生成AIモデルであるTransformerもAttention Mechanismをベースにしています。
つまり昨今流行りに流行っている生成AIに関して、使うことは簡単だけど結局何がすごいの?どんな技術が使われているの?と思っていたわけですが、Attention MechanismをベースにしたTransformerなどの深層学習モデルについて知ることのできるスタートラインにようやく立てたとも言えます。
正直仕事の後で深夜までモデルが動かずに大変な思いをした日もありましたが、当初の目的を果たせたという点に関しては及第点をあげてもいいのかなと思います。
そんなこんなで折角学んだ技術を今度は使うことでより理解を深めていきたいとは思っていますが、きりの良いこの辺りで一度立ち止まって今後について少し考えたいと思います。
近いうちに学んだことに関して少しまとめるので、そこでこれからの進め方に関して言及できればと思います。
ということで、とりあえずは100日間ありがとうございました。
■参考文献
- Andreas C. Muller, Sarah Guido. Pythonではじめる機械学習. 中田 秀基 訳. オライリー・ジャパン. 2017. 392p.
- 斎藤 康毅. ゼロから作るDeep Learning Pythonで学ぶディープラーニングの理論と実装. オライリー・ジャパン. 2016. 320p.
- 斎藤 康毅. ゼロから作るDeep Learning② 自然言語処理編. オライリー・ジャパン. 2018. 432p.
- ChatGPT. 4o mini. OpenAI. 2024. https://chatgpt.com/
- API Reference. scikit-learn.org. https://scikit-learn.org/stable/api/index.html
- PyTorch documentation. pytorch.org. https://pytorch.org/docs/stable/index.html
- Keiron O’Shea, Ryan Nash. An Introduction to Convolutional Neural Networks. https://ar5iv.labs.arxiv.org/html/1511.08458
- API Reference. scipy.org. 2024. https://docs.scipy.org/doc/scipy/reference/index.html