AIって結局何なのかよく分からないので、とりあえず100日間勉強してみた Day95
経緯についてはこちらをご参照ください。
■本日の進捗
- LSTMの性能を向上
■はじめに
今回も「ゼロから作るDeep Learning② 自然言語処理編(オライリー・ジャパン)」から学んでいきます。
今回は、これまで実装してきたLSTM言語モデルの性能を向上するための手法をいくつか取り入れたいと思います。
■多層化
実装してきた言語モデルを更に性能の良いモデルにする方法を考えていきます。まずは当たり前のこと(starting the obvious)ですが、RNNもLSTMもニューラルネットワークの一種です。ニューラルネットワークの表現力を上げるのに最も簡単に思いつく方法は多層化です。層を増やせば増やすほどニューラルネットは(もはや人間が理解することが不可能なレベルまで)複雑になり、その表現力も大きく向上することが期待されます。
PTBデータセットの場合は、LSTMを2層から4層重ねると良い結果が得られると言われており、Google翻訳で使われているGNMTモデルはLSTMを8層重ねているそうです。Google翻訳を使ったことのない人はいないと思いますが、LSTMを8層重ねることであれほどまでに自然な言葉を紡ぎ出せるということには感動を覚えます。(もちろん8層はかなり多いですしデータセットの質と量の方が重要なことはこれまで何度も学んできました。)
■Dropout
多層化することでモデルの表現力が上がることは、これまで学んできた通りですが、モデルが複雑になるということはそれと同時にモデルがデータセットに過剰適合してしまうということもこれまで学んできた通りです。
多層化を行う際には同時にこの過学習の抑制についても考慮する必要があります。このような目的に対しては正則化等様々な方法がありますが、ニューラルネットワークではランダムでニューロン(ノード)を不活性化するDropoutが有効でした。
今回のDropoutにも時系列処理に対応した形にする必要があります。
まずはDropoutでの不活性化の割合(dropout_ratio)を指定します。self.paramsやself.gradsを初期化させますが、どのノードを不活性化するかを保持するために、self.maskを定義しておきます。また、推論時にはDropout自体の処理は行わないので、フラグ(self.train_flg)を設定しておきます。
class TimeDropout:
def __init__(self, dropout_ratio=0.5):
self.params, self.grads = [], []
self.dropout_ratio = dropout_ratio
self.mask = None
self.train_flg = True
順伝播の場合には、self.train_flgがTrueの場合にのみ実行します。入力データ(xs)と同じ形状のランダムな数値の入った配列を生成し、Dropout率より大きければTrue、小さければFalseをflg変数に格納します。無効化されていないノードの出力をスケールアップして、Dropout後の出力が入力の総和と一致するように調整します。self.maskにはこれらをかけた値を格納して、入力データ(xs)にself.maskをかけた値を返します。
def forward(self, xs):
if self.train_flg:
flg = np.random.rand(*xs.shape) > self.dropout_ratio
scale = 1 / (1.0 - self.dropout_ratio)
self.mask = flg.astype(np.float32) * scale
return xs * self.mask
else:
return xs
逆伝播の場合は、順伝播で不活性化したノードの勾配も0に無効化した値を返します。
def backward(self, dout):
return dout * self.mask
■重み共有
さらにモデルの複雑さを抑制するために重み共有という手法を適用します。ここでは、Embedding層と全結合層で重みを共有しますが、これにより学習で更新する要素(モデルの自由度)が減ります。これは実装が簡単なだけでなく計算コストの削減にも繋がります。
■LSTM言語モデルの改善
それでは、上記の手法を取り入れて性能向上を目指したLSTM言語モデルを実装します。といっても先ほどのDropout以外はほとんど以前のLSTM言語モデルと同じです。ここではLSTM層を2層に多層化し、その前後にDropoutを適用します。また、最初と最後であるEmbedding層と全結合層では重みを共有します。
class BetterRnnlm(Rnnlm):
def __init__(self, vocab_size=10000, wordvec_size=650,
hidden_size=650, dropout_ratio=0.5):
V, D, H = vocab_size, wordvec_size, hidden_size
rn = np.random.randn
embed_W = (rn(V, D) / 100).astype('f')
lstm_Wx1 = (rn(D, 4 * H) / np.sqrt(D)).astype('f')
lstm_Wh1 = (rn(H, 4 * H) / np.sqrt(H)).astype('f')
lstm_b1 = np.zeros(4 * H).astype('f')
lstm_Wx2 = (rn(H, 4 * H) / np.sqrt(H)).astype('f')
lstm_Wh2 = (rn(H, 4 * H) / np.sqrt(H)).astype('f')
lstm_b2 = np.zeros(4 * H).astype('f')
affine_b = np.zeros(V).astype('f')
self.layers = [
TimeEmbedding(embed_W),
TimeDropout(dropout_ratio),
TimeLSTM(lstm_Wx1, lstm_Wh1, lstm_b1, stateful=True),
TimeDropout(dropout_ratio),
TimeLSTM(lstm_Wx2, lstm_Wh2, lstm_b2, stateful=True),
TimeDropout(dropout_ratio),
TimeAffine(embed_W.T, affine_b)
]
self.loss_layer = TimeSoftmaxWithLoss()
self.lstm_layers = [self.layers[2], self.layers[4]]
self.drop_layers = [self.layers[1], self.layers[3], self.layers[5]]
self.params, self.grads = [], []
for layer in self.layers:
self.params += layer.params
self.grads += layer.grads
def predict(self, xs, train_flg=False):
for layer in self.drop_layers:
layer.train_flg = train_flg
for layer in self.layers:
xs = layer.forward(xs)
return xs
def forward(self, xs, ts, train_flg=True):
score = self.predict(xs, train_flg)
loss = self.loss_layer.forward(score, ts)
return loss
def backward(self, dout=1):
dout = self.loss_layer.backward(dout)
for layer in reversed(self.layers):
dout = layer.backward(dout)
return dout
def reset_state(self):
for layer in self.lstm_layers:
layer.reset_state()
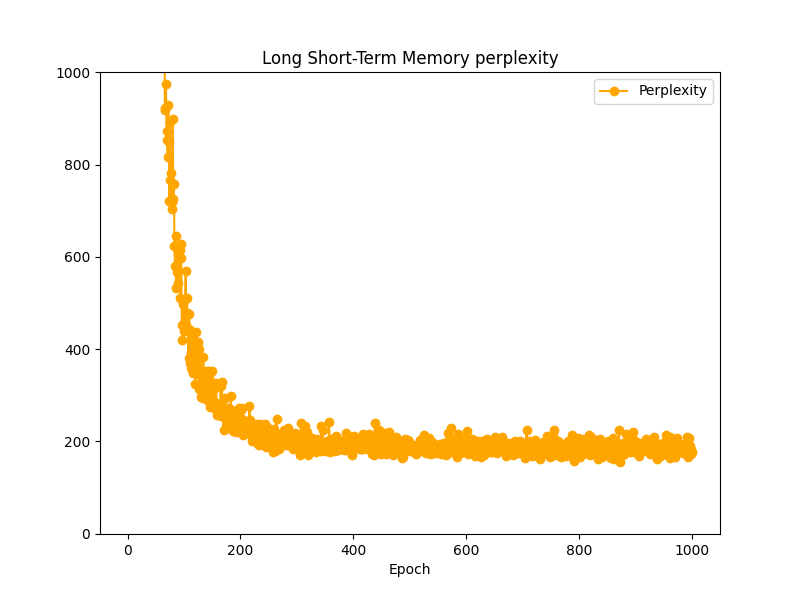
このモデルを用いて学習させた結果です。学習ループはこれまでと同様で、時系列データを20の時のPerplexityは、およそ180前後で学習が止まっています。
ここまでで3つの言語モデルを作成してきたので、これらのPerplexityを今一度並べてみます。
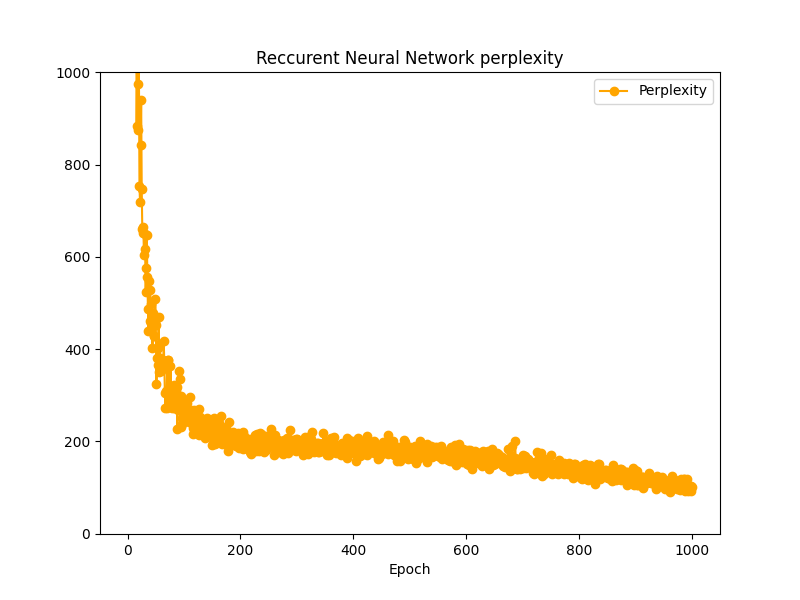
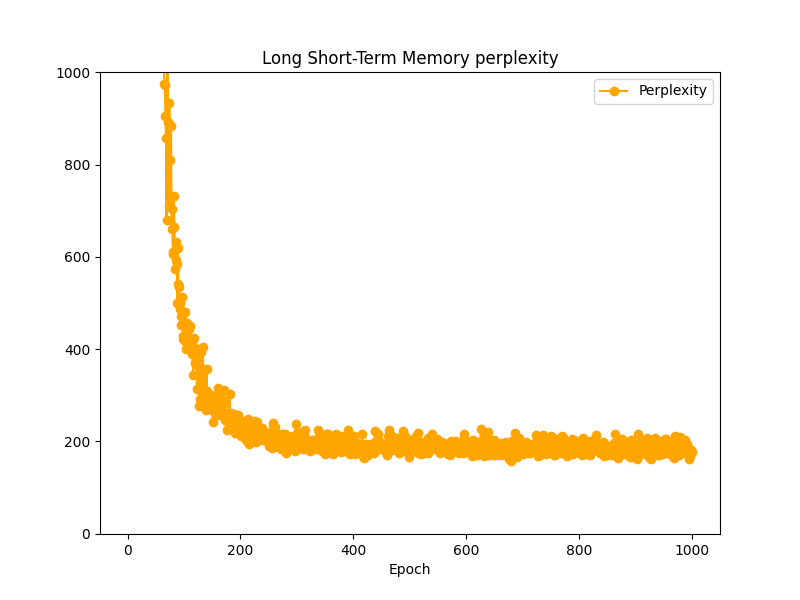
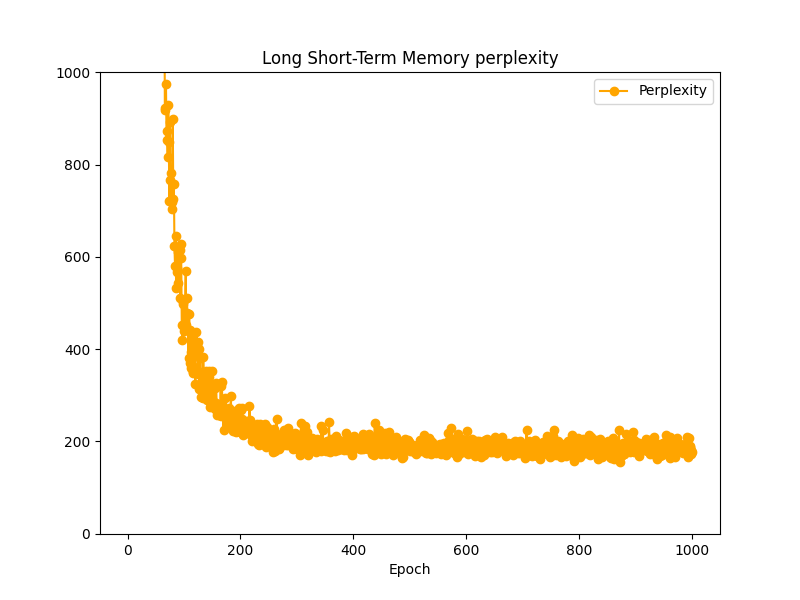
■おわりに
今回は多層化、Dropout、重み共有を用いてLSTM言語モデルを性能向上させてみました。結果を並べてみましたがほとんど変わりませんでした。これはデータセットの適用方法に問題があった可能性があります。ただ、全データを適用するとCPUシングルプロセスには重すぎるので、適切な学習はまたの機会にしたいと思います。
■参考文献
- Andreas C. Muller, Sarah Guido. Pythonではじめる機械学習. 中田 秀基 訳. オライリー・ジャパン. 2017. 392p.
- 斎藤 康毅. ゼロから作るDeep Learning Pythonで学ぶディープラーニングの理論と実装. オライリー・ジャパン. 2016. 320p.
- 斎藤 康毅. ゼロから作るDeep Learning② 自然言語処理編. オライリー・ジャパン. 2018. 432p.
- ChatGPT. 4o mini. OpenAI. 2024. https://chatgpt.com/
- API Reference. scikit-learn.org. https://scikit-learn.org/stable/api/index.html
- PyTorch documentation. pytorch.org. https://pytorch.org/docs/stable/index.html
- Keiron O’Shea, Ryan Nash. An Introduction to Convolutional Neural Networks. https://ar5iv.labs.arxiv.org/html/1511.08458
- API Reference. scipy.org. 2024. https://docs.scipy.org/doc/scipy/reference/index.html