AIって結局何なのかよく分からないので、とりあえず100日間勉強してみた Day94
経緯についてはこちらをご参照ください。
■本日の進捗
- LSTMの学習を実装
■はじめに
今回も「ゼロから作るDeep Learning② 自然言語処理編(オライリー・ジャパン)」から学んでいきます。
今回は、前回実装したLSTM言語モデルクラスを学習させていきたいと思います。
■RNN言語モデルの学習
LSTM言語モデルを学習させていこうと思いますが、まずはRNN言語モデルを振り返ります。RNNは優秀な言語モデルを構成する層ですが、長期的な記憶が必要な場合には、計算コストや勾配爆発、勾配消失の観点から問題が起こりやすいのでした。
RNNの時系列数を増やして学習させてみます。
import sys
import os
sys.path.append('..')
import numpy as np
import matplotlib.pyplot as plt
import pickle
from sklearn.utils.extmath import randomized_svd
import collections
GPU = False
key_file = {
'train':'ptb.train.txt',
'test':'ptb.test.txt',
'valid':'ptb.valid.txt'
}
save_file = {
'train':'ptb.train.npy',
'test':'ptb.test.npy',
'valid':'ptb.valid.npy'
}
vocab_file = 'ptb.vocab.pkl'
dataset_dir = os.path.dirname(os.path.abspath(__file__))
mid_path = '..\..\Download_Dataset\lstm-master\data'
def load_vocab():
vocab_path = os.path.join(dataset_dir, vocab_file)
print(vocab_path)
if os.path.exists(vocab_path):
with open(vocab_path, 'rb') as f:
word_to_id, id_to_word = pickle.load(f)
return word_to_id, id_to_word
word_to_id = {}
id_to_word = {}
data_type = 'train'
file_name = key_file[data_type]
file_path = os.path.join(dataset_dir, mid_path, file_name)
words = open(file_path).read().replace('\n', '<eos>').strip().split()
for i, word in enumerate(words):
if word not in word_to_id:
tmp_id = len(word_to_id)
word_to_id[word] = tmp_id
id_to_word[tmp_id] = word
with open(vocab_path, 'wb') as f:
pickle.dump((word_to_id, id_to_word), f)
return word_to_id, id_to_word
def load_data(data_type='train'):
if data_type == 'val': data_type = 'valid'
save_path = dataset_dir + '\\' + save_file[data_type]
print('save_path:', save_path)
word_to_id, id_to_word = load_vocab()
if os.path.exists(save_path):
corpus = np.load(save_path)
return corpus, word_to_id, id_to_word
file_name = key_file[data_type]
file_path = os.path.join(dataset_dir, mid_path, file_name)
words = open(file_path).read().replace('\n', '<eos>').strip().split()
corpus = np.array([word_to_id[w] for w in words])
np.save(save_path, corpus)
return corpus, word_to_id, id_to_word
class Embedding:
def __init__(self, W):
self.params = [W]
self.grads = [np.zeros_like(W)]
self.idx = None
def forward(self, idx):
W, = self.params
self.idx = idx
out = W[idx]
return out
def backward(self, dout):
dW, = self.grads
dW[...] = 0
if GPU:
np.scatter_add(dW, self.idx, dout)
else:
np.add.at(dW, self.idx, dout)
return None
def softmax(x):
if x.ndim == 2:
x = x - x.max(axis=1, keepdims=True)
x = np.exp(x)
x /= x.sum(axis=1, keepdims=True)
elif x.ndim == 1:
x = x - np.max(x)
x = np.exp(x) / np.sum(np.exp(x))
return x
class RNN:
def __init__(self, Wx, Wh, b):
self.params = [Wx, Wh, b]
self.grads = [np.zeros_like(Wx), np.zeros_like(Wh), np.zeros_like(b)]
self.cache = None
def forward(self, x, h_prev):
Wx, Wh, b = self.params
t = np.dot(h_prev, Wh) + np.dot(x, Wx) + b
h_next = np.tanh(t)
self.cache = (x, h_prev, h_next)
return h_next
def backward(self, dh_next):
Wx, Wh, b = self.params
x, h_prev, h_next = self.cache
dt = dh_next * (1 - h_next ** 2)
db = np.sum(dt, axis=0)
dWh = np.dot(h_prev.T, dt)
dh_prev = np.dot(dt, Wh.T)
dWx = np.dot(x.T, dt)
dx = np.dot(dt, Wx.T)
self.grads[0][...] = dWx
self.grads[1][...] = dWh
self.grads[2][...] = db
return dx, dh_prev
class TimeRNN:
def __init__(self, Wx, Wh, b, stateful=False):
self.params = [Wx, Wh, b]
self.grads = [np.zeros_like(Wx), np.zeros_like(Wh), np.zeros_like(b)]
self.layers = None
self.h, self.dh = None, None
self.stateful = stateful
def forward(self, xs):
Wx, Wh, b = self.params
N, T, D = xs.shape
D, H = Wx.shape
self.layers = []
hs = np.empty((N, T, H), dtype='f')
if not self.stateful or self.h is None:
self.h = np.zeros((N, H), dtype='f')
for t in range(T):
layer = RNN(*self.params)
self.h = layer.forward(xs[:, t, :], self.h)
hs[:, t, :] = self.h
self.layers.append(layer)
return hs
def backward(self, dhs):
Wx, Wh, b = self.params
N, T, H = dhs.shape
D, H = Wx.shape
dxs = np.empty((N, T, D), dtype='f')
dh = 0
grads = [0, 0, 0]
for t in reversed(range(T)):
layer = self.layers[t]
dx, dh = layer.backward(dhs[:, t, :] + dh)
dxs[:, t, :] = dx
for i, grad in enumerate(layer.grads):
grads[i] += grad
for i, grad in enumerate(grads):
self.grads[i][...] = grad
self.dh = dh
return dxs
def set_state(self, h):
self.h = h
def reset_state(self):
self.h = None
class TimeEmbedding:
def __init__(self, W):
self.params = [W]
self.grads = [np.zeros_like(W)]
self.layers = None
self.W = W
def forward(self, xs):
N, T = xs.shape
V, D = self.W.shape
out = np.empty((N, T, D), dtype='f')
self.layers = []
for t in range(T):
layer = Embedding(self.W)
out[:, t, :] = layer.forward(xs[:, t])
self.layers.append(layer)
return out
def backward(self, dout):
N, T, D = dout.shape
grad = 0
for t in range(T):
layer = self.layers[t]
layer.backward(dout[:, t, :])
grad += layer.grads[0]
self.grads[0][...] = grad
return None
class TimeAffine:
def __init__(self, W, b):
self.params = [W, b]
self.grads = [np.zeros_like(W), np.zeros_like(b)]
self.x = None
def forward(self, x):
N, T, D = x.shape
W, b = self.params
rx = x.reshape(N*T, -1)
out = np.dot(rx, W) + b
self.x = x
return out.reshape(N, T, -1)
def backward(self, dout):
x = self.x
N, T, D = x.shape
W, b = self.params
dout = dout.reshape(N*T, -1)
rx = x.reshape(N*T, -1)
db = np.sum(dout, axis=0)
dW = np.dot(rx.T, dout)
dx = np.dot(dout, W.T)
dx = dx.reshape(*x.shape)
self.grads[0][...] = dW
self.grads[1][...] = db
return dx
class TimeSoftmaxWithLoss:
def __init__(self):
self.params, self.grads = [], []
self.cache = None
self.ignore_label = -1
def forward(self, xs, ts):
N, T, V = xs.shape
if ts.ndim == 3:
ts = ts.argmax(axis=2)
mask = (ts != self.ignore_label)
xs = xs.reshape(N * T, V)
ts = ts.reshape(N * T)
mask = mask.reshape(N * T)
ys = softmax(xs)
ls = np.log(ys[np.arange(N * T), ts])
ls *= mask
loss = -np.sum(ls)
loss /= mask.sum()
self.cache = (ts, ys, mask, (N, T, V))
return loss
def backward(self, dout=1):
ts, ys, mask, (N, T, V) = self.cache
dx = ys
dx[np.arange(N * T), ts] -= 1
dx *= dout
dx /= mask.sum()
dx *= mask[:, np.newaxis]
dx = dx.reshape((N, T, V))
return dx
class SimpleRnnlm:
def __init__(self, vocab_size, wordvec_size, hidden_size):
V, D, H = vocab_size, wordvec_size, hidden_size
rn = np.random.randn
embed_W = (rn(V, D) / 100).astype('f')
rnn_Wx = (rn(D, H) / np.sqrt(D)).astype('f')
rnn_Wh = (rn(H, H) / np.sqrt(H)).astype('f')
rnn_b = np.zeros(H).astype('f')
affine_W = (rn(H, V) / np.sqrt(H)).astype('f')
affine_b = np.zeros(V).astype('f')
self.layers = [
TimeEmbedding(embed_W),
TimeRNN(rnn_Wx, rnn_Wh, rnn_b, stateful=True),
TimeAffine(affine_W, affine_b)
]
self.loss_layer = TimeSoftmaxWithLoss()
self.rnn_layer = self.layers[1]
self.params, self.grads = [], []
for layer in self.layers:
self.params += layer.params
self.grads += layer.grads
def forward(self, xs, ts):
for layer in self.layers:
xs = layer.forward(xs)
loss = self.loss_layer.forward(xs, ts)
return loss
def backward(self, dout=1):
dout = self.loss_layer.backward(dout)
for layer in reversed(self.layers):
dout = layer.backward(dout)
return dout
def reset_state(self):
self.rnn_layer.reset_state()
corpus, word_to_id, id_to_word = load_data('train')
corpus = corpus[:10000]
batch_size = 10
wordvec_size = 100
hidden_size = 100
time_size = 20
lr = 0.1
max_epoch = 1000
vocab_size = len(word_to_id)
xs = corpus[:-1]
ts = corpus[1:]
data_size = len(xs)
def create_batch(xs, ts, batch_size, time_size):
batch_x = np.zeros((batch_size, time_size), dtype=np.int32)
batch_t = np.zeros((batch_size, time_size), dtype=np.int32)
for i in range(batch_size):
start_idx = np.random.randint(0, len(xs) - time_size)
batch_x[i] = xs[start_idx:start_idx + time_size]
batch_t[i] = ts[start_idx:start_idx + time_size]
return batch_x, batch_t
model = SimpleRnnlm(vocab_size, wordvec_size, hidden_size)
loss_list = []
ppl_list = []
loss_count = 0
for epoch in range(max_epoch):
total_loss = 0
for _ in range(data_size // (batch_size * time_size)):
batch_x, batch_t = create_batch(xs, ts, batch_size, time_size)
loss = model.forward(batch_x, batch_t)
model.backward()
for param, grad in zip(model.params, model.grads):
param -= lr * grad
total_loss += loss
loss_count += 1
avg_loss = total_loss / (data_size // (batch_size * time_size))
loss_list.append(avg_loss)
print(f"Epoch {epoch+1}/{max_epoch}, Loss: {avg_loss:.4f}")
ppl = np.exp(total_loss / loss_count)
print(f"Epoch {epoch+1}/{max_epoch}, Perplexity: {ppl}")
ppl_list.append(float(ppl))
loss_count = 0
plt.figure(figsize=(8, 6))
plt.plot(range(1, max_epoch + 1), ppl_list, marker='o', color='orange', label='Perplexity')
plt.xlabel('Epoch')
plt.legend()
plt.ylim(-0.5, 1000.5)
plt.title('Reccurent Neural Network perplexity')
plt.show()
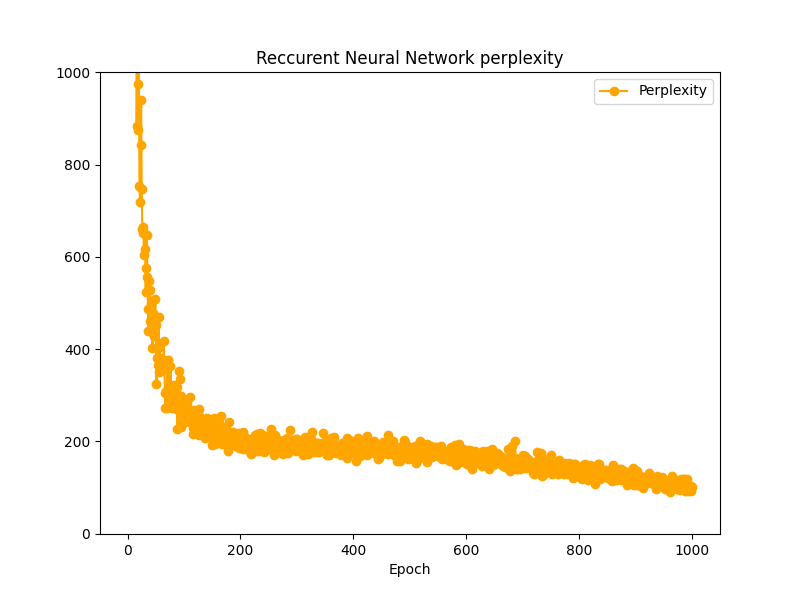
時系列データを20で学習させてみました。Perplexityを指標にすると、1000エポックでPerplexity200をようやく下回ってきたくらいでしょうか。
時系列データが5の時と比べるとだいぶ苦戦をしているようですが、それでももっとエポック数を増やせば学習は進みそうです。思ったよりRNN言語モデルの性能は悪くなさそうに見えます。
■LSTM言語モデルの学習
続いてLSTM言語モデルを学習させていきます。といってもここまで構築してきたクラスを用いれば学習ループはほとんどそのまま流用できます。
ただし、LSTM言語モデルクラスはforwardメソッドを推論と学習(損失誤差)に分離したpredictとforwardを備えているのでその点のみ注意が必要です。
import sys
import os
sys.path.append('..')
import numpy as np
import matplotlib.pyplot as plt
import pickle
from sklearn.utils.extmath import randomized_svd
import collections
GPU = False
key_file = {
'train':'ptb.train.txt',
'test':'ptb.test.txt',
'valid':'ptb.valid.txt'
}
save_file = {
'train':'ptb.train.npy',
'test':'ptb.test.npy',
'valid':'ptb.valid.npy'
}
vocab_file = 'ptb.vocab.pkl'
dataset_dir = os.path.dirname(os.path.abspath(__file__))
mid_path = '..\..\Download_Dataset\lstm-master\data'
def load_vocab():
vocab_path = os.path.join(dataset_dir, vocab_file)
print(vocab_path)
if os.path.exists(vocab_path):
with open(vocab_path, 'rb') as f:
word_to_id, id_to_word = pickle.load(f)
return word_to_id, id_to_word
word_to_id = {}
id_to_word = {}
data_type = 'train'
file_name = key_file[data_type]
file_path = os.path.join(dataset_dir, mid_path, file_name)
words = open(file_path).read().replace('\n', '<eos>').strip().split()
for i, word in enumerate(words):
if word not in word_to_id:
tmp_id = len(word_to_id)
word_to_id[word] = tmp_id
id_to_word[tmp_id] = word
with open(vocab_path, 'wb') as f:
pickle.dump((word_to_id, id_to_word), f)
return word_to_id, id_to_word
def load_data(data_type='train'):
if data_type == 'val': data_type = 'valid'
save_path = dataset_dir + '\\' + save_file[data_type]
print('save_path:', save_path)
word_to_id, id_to_word = load_vocab()
if os.path.exists(save_path):
corpus = np.load(save_path)
return corpus, word_to_id, id_to_word
file_name = key_file[data_type]
file_path = os.path.join(dataset_dir, mid_path, file_name)
words = open(file_path).read().replace('\n', '<eos>').strip().split()
corpus = np.array([word_to_id[w] for w in words])
np.save(save_path, corpus)
return corpus, word_to_id, id_to_word
class Embedding:
def __init__(self, W):
self.params = [W]
self.grads = [np.zeros_like(W)]
self.idx = None
def forward(self, idx):
W, = self.params
self.idx = idx
out = W[idx]
return out
def backward(self, dout):
dW, = self.grads
dW[...] = 0
if GPU:
np.scatter_add(dW, self.idx, dout)
else:
np.add.at(dW, self.idx, dout)
return None
def softmax(x):
if x.ndim == 2:
x = x - x.max(axis=1, keepdims=True)
x = np.exp(x)
x /= x.sum(axis=1, keepdims=True)
elif x.ndim == 1:
x = x - np.max(x)
x = np.exp(x) / np.sum(np.exp(x))
return x
def sigmoid(x):
return 1 / (1 + np.exp(-x))
class LSTM:
def __init__(self, Wx, Wh, b):
self.params = [Wx, Wh, b]
self.grads = [np.zeros_like(Wx), np.zeros_like(Wh), np.zeros_like(b)]
self.cache = None
def forward(self, x, h_prev, c_prev):
Wx, Wh, b = self.params
N, H = h_prev.shape
A = np.dot(x, Wx) + np.dot(h_prev, Wh) + b
f = A[:, :H]
g = A[:, H:2*H]
i = A[:, 2*H:3*H]
o = A[:, 3*H:]
f = sigmoid(f)
g = np.tanh(g)
i = sigmoid(i)
o = sigmoid(o)
c_next = f * c_prev + g * i
h_next = o * np.tanh(c_next)
self.cache = (x, h_prev, c_prev, i, f, g, o, c_next)
return h_next, c_next
def backward(self, dh_next, dc_next):
Wx, Wh, b = self.params
x, h_prev, c_prev, i, f, g, o, c_next = self.cache
tanh_c_next = np.tanh(c_next)
ds = dc_next + (dh_next * o) * (1 - tanh_c_next ** 2)
dc_prev = ds * f
di = ds * g
df = ds * c_prev
do = dh_next * tanh_c_next
dg = ds * i
di *= i * (1 - i)
df *= f * (1 - f)
do *= o * (1 - o)
dg *= (1 - g ** 2)
dA = np.hstack((df, dg, di, do))
dWh = np.dot(h_prev.T, dA)
dWx = np.dot(x.T, dA)
db = dA.sum(axis=0)
self.grads[0][...] = dWx
self.grads[1][...] = dWh
self.grads[2][...] = db
dx = np.dot(dA, Wx.T)
dh_prev = np.dot(dA, Wh.T)
return dx, dh_prev, dc_prev
class TimeLSTM:
def __init__(self, Wx, Wh, b, stateful=False):
self.params = [Wx, Wh, b]
self.grads = [np.zeros_like(Wx), np.zeros_like(Wh), np.zeros_like(b)]
self.layers = None
self.h, self.c = None, None
self.dh = None
self.stateful = stateful
def forward(self, xs):
Wx, Wh, b = self.params
N, T, D = xs.shape
H = Wh.shape[0]
self.layers = []
hs = np.empty((N, T, H), dtype='f')
if not self.stateful or self.h is None:
self.h = np.zeros((N, H), dtype='f')
if not self.stateful or self.c is None:
self.c = np.zeros((N, H), dtype='f')
for t in range(T):
layer = LSTM(*self.params)
self.h, self.c = layer.forward(xs[:, t, :], self.h, self.c)
hs[:, t, :] = self.h
self.layers.append(layer)
return hs
def backward(self, dhs):
Wx, Wh, b = self.params
N, T, H = dhs.shape
D = Wx.shape[0]
dxs = np.empty((N, T, D), dtype='f')
dh, dc = 0, 0
grads = [0, 0, 0]
for t in reversed(range(T)):
layer = self.layers[t]
dx, dh, dc = layer.backward(dhs[:, t, :] + dh, dc)
dxs[:, t, :] = dx
for i, grad in enumerate(layer.grads):
grads[i] += grad
for i, grad in enumerate(grads):
self.grads[i][...] = grad
self.dh = dh
return dxs
def set_state(self, h, c=None):
self.h, self.c = h, c
def reset_state(self):
self.h, self.c = None, None
class TimeEmbedding:
def __init__(self, W):
self.params = [W]
self.grads = [np.zeros_like(W)]
self.layers = None
self.W = W
def forward(self, xs):
N, T = xs.shape
V, D = self.W.shape
out = np.empty((N, T, D), dtype='f')
self.layers = []
for t in range(T):
layer = Embedding(self.W)
out[:, t, :] = layer.forward(xs[:, t])
self.layers.append(layer)
return out
def backward(self, dout):
N, T, D = dout.shape
grad = 0
for t in range(T):
layer = self.layers[t]
layer.backward(dout[:, t, :])
grad += layer.grads[0]
self.grads[0][...] = grad
return None
class TimeAffine:
def __init__(self, W, b):
self.params = [W, b]
self.grads = [np.zeros_like(W), np.zeros_like(b)]
self.x = None
def forward(self, x):
N, T, D = x.shape
W, b = self.params
rx = x.reshape(N*T, -1)
out = np.dot(rx, W) + b
self.x = x
return out.reshape(N, T, -1)
def backward(self, dout):
x = self.x
N, T, D = x.shape
W, b = self.params
dout = dout.reshape(N*T, -1)
rx = x.reshape(N*T, -1)
db = np.sum(dout, axis=0)
dW = np.dot(rx.T, dout)
dx = np.dot(dout, W.T)
dx = dx.reshape(*x.shape)
self.grads[0][...] = dW
self.grads[1][...] = db
return dx
class TimeSoftmaxWithLoss:
def __init__(self):
self.params, self.grads = [], []
self.cache = None
self.ignore_label = -1
def forward(self, xs, ts):
N, T, V = xs.shape
if ts.ndim == 3:
ts = ts.argmax(axis=2)
mask = (ts != self.ignore_label)
xs = xs.reshape(N * T, V)
ts = ts.reshape(N * T)
mask = mask.reshape(N * T)
ys = softmax(xs)
ls = np.log(ys[np.arange(N * T), ts])
ls *= mask
loss = -np.sum(ls)
loss /= mask.sum()
self.cache = (ts, ys, mask, (N, T, V))
return loss
def backward(self, dout=1):
ts, ys, mask, (N, T, V) = self.cache
dx = ys
dx[np.arange(N * T), ts] -= 1
dx *= dout
dx /= mask.sum()
dx *= mask[:, np.newaxis]
dx = dx.reshape((N, T, V))
return dx
class Rnnlm:
def __init__(self, vocab_size=10000, wordvec_size=100, hidden_size=100):
V, D, H = vocab_size, wordvec_size, hidden_size
rn = np.random.randn
embed_W = (rn(V, D) / 100).astype('f')
lstm_Wx = (rn(D, 4 * H) / np.sqrt(D)).astype('f')
lstm_Wh = (rn(H, 4 * H) / np.sqrt(H)).astype('f')
lstm_b = np.zeros(4 * H).astype('f')
affine_W = (rn(H, V) / np.sqrt(H)).astype('f')
affine_b = np.zeros(V).astype('f')
self.layers = [
TimeEmbedding(embed_W),
TimeLSTM(lstm_Wx, lstm_Wh, lstm_b, stateful=True),
TimeAffine(affine_W, affine_b)
]
self.loss_layer = TimeSoftmaxWithLoss()
self.lstm_layer = self.layers[1]
self.params, self.grads = [], []
for layer in self.layers:
self.params += layer.params
self.grads += layer.grads
def predict(self, xs):
for layer in self.layers:
xs = layer.forward(xs)
return xs
def forward(self, xs, ts):
score = self.predict(xs)
loss = self.loss_layer.forward(score, ts)
return loss
def backward(self, dout=1):
dout = self.loss_layer.backward(dout)
for layer in reversed(self.layers):
dout = layer.backward(dout)
return dout
def reset_state(self):
self.lstm_layer.reset_state()
def save_params(self, file_name='Rnnlm.pkl'):
with open(file_name, 'wb') as f:
pickle.dump(self.params, f)
def load_params(self, file_name='Rnnlm.pkl'):
with open(file_name, 'rb') as f:
self.params = pickle.load(f)
corpus, word_to_id, id_to_word = load_data('train')
corpus = corpus[:10000]
batch_size = 10
wordvec_size = 100
hidden_size = 100
time_size = 20
lr = 0.1
max_epoch = 1000
vocab_size = len(word_to_id)
xs = corpus[:-1]
ts = corpus[1:]
data_size = len(xs)
def create_batch(xs, ts, batch_size, time_size):
batch_x = np.zeros((batch_size, time_size), dtype=np.int32)
batch_t = np.zeros((batch_size, time_size), dtype=np.int32)
for i in range(batch_size):
start_idx = np.random.randint(0, len(xs) - time_size)
batch_x[i] = xs[start_idx:start_idx + time_size]
batch_t[i] = ts[start_idx:start_idx + time_size]
return batch_x, batch_t
model = Rnnlm(vocab_size, wordvec_size, hidden_size)
loss_list = []
ppl_list = []
loss_count = 0
for epoch in range(max_epoch):
total_loss = 0
for _ in range(data_size // (batch_size * time_size)):
batch_x, batch_t = create_batch(xs, ts, batch_size, time_size)
model.predict(batch_x)
loss = model.forward(batch_x, batch_t)
model.backward()
for param, grad in zip(model.params, model.grads):
param -= lr * grad
total_loss += loss
loss_count += 1
avg_loss = total_loss / (data_size // (batch_size * time_size))
loss_list.append(avg_loss)
print(f"Epoch {epoch+1}/{max_epoch}, Loss: {avg_loss:.4f}")
ppl = np.exp(total_loss / loss_count)
print(f"Epoch {epoch+1}/{max_epoch}, Perplexity: {ppl}")
ppl_list.append(float(ppl))
loss_count = 0
plt.figure(figsize=(8, 6))
plt.plot(range(1, max_epoch + 1), ppl_list, marker='o', color='orange', label='Perplexity')
plt.xlabel('Epoch')
plt.legend()
plt.ylim(-0.5, 1000.5)
plt.title('Long Short-Term Memory perplexity')
plt.show()
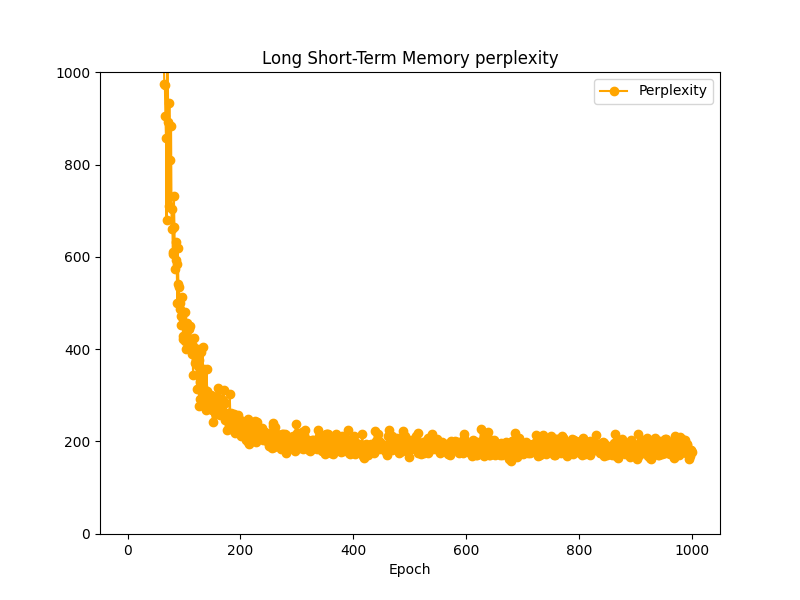
LSTM言語モデルではPerplexity200で高止まりしていて、これ以上学習が進みそうもありませんでした。
■おわりに
検証においては時系列データを90程度まで上げましたが、上記の結果とそれほど変わりませんでした。そもそもそれほど大規模ではないPTBデータセットを1000個までしか使っていなかったりで、あまりLSTMの有用性が見えにくかったのかもしれません。
■参考文献
- Andreas C. Muller, Sarah Guido. Pythonではじめる機械学習. 中田 秀基 訳. オライリー・ジャパン. 2017. 392p.
- 斎藤 康毅. ゼロから作るDeep Learning Pythonで学ぶディープラーニングの理論と実装. オライリー・ジャパン. 2016. 320p.
- 斎藤 康毅. ゼロから作るDeep Learning② 自然言語処理編. オライリー・ジャパン. 2018. 432p.
- ChatGPT. 4o mini. OpenAI. 2024. https://chatgpt.com/
- API Reference. scikit-learn.org. https://scikit-learn.org/stable/api/index.html
- PyTorch documentation. pytorch.org. https://pytorch.org/docs/stable/index.html
- Keiron O’Shea, Ryan Nash. An Introduction to Convolutional Neural Networks. https://ar5iv.labs.arxiv.org/html/1511.08458
- API Reference. scipy.org. 2024. https://docs.scipy.org/doc/scipy/reference/index.html