AIって結局何なのかよく分からないので、とりあえず100日間勉強してみた Day84
経緯についてはこちらをご参照ください。
■本日の進捗
- Negative Samplingの実装を理解
■はじめに
今回も「ゼロから作るDeep Learning② 自然言語処理編(オライリー・ジャパン)」から学んでいきます。
今回は、コーパスが増えることによるソフトマックスの計算負荷増大を回避するためのNegative Samplingを学んでいきます。
■Negative Sampling 学習の実装
前回作成したEmbeddingDotクラス、UnigramSamplerクラス、SigmoidWithLossクラス、NegativeSamplingLossクラスを用いて、実際にNegative Samplingで学習を行うようにしていきます。
なお、Negative Samplingの学習の実装にあたっては、これまでのクラスや関数を含めていくつかの変更を加えました。そのほとんどは機能性や効率性ではなく行列積などにおける行列形状の不一致に対応したもので、広範囲に及びます。
そのため(忘備録としての機能を失いかけていますが…)ここでは変化点に対する説明は残しません。基本的なコードの流れは通常のニューラルネットワークによる学習と全く一緒なので、この機会に頭からソースを追ってみるのはどうでしょうか。
import numpy as np
import matplotlib.pyplot as plt
import collections
GPU = False
class MatMul:
def __init__(self, W):
self.params = [W]
self.grads = [np.zeros_like(W)]
self.x = None
def forward(self, x):
W, = self.params
out = np.dot(x, W)
self.x = x
return out
def backward(self, dout):
W, = self.params
dx = np.dot(dout, W.T)
dW = np.dot(self.x.T, dout)
self.grads[0][...] = dW
return dx
class Embedding:
def __init__(self, W):
self.params = [W]
self.grads = [np.zeros_like(W)]
self.idx = None
def forward(self, idx):
W, = self.params
self.idx = idx
out = W[idx]
return out
def backward(self, dout):
dW, = self.grads
dW[...] = 0
for i, word_id in enumerate(self.idx):
dW[word_id] += dout[i]
return None
class EmbeddingDot:
def __init__(self, vocab_size, embedding_dim):
self.W = np.random.randn(vocab_size, embedding_dim) * 0.01
self.embed = Embedding(self.W)
self.params = [self.W]
self.grads = [np.zeros_like(self.W)]
self.cache = None
def forward(self, h, idx):
target_W = self.embed.forward(idx)
out = np.sum(target_W * h, axis=1)
self.cache = (h, target_W)
return out
def backward(self, dout):
h, target_W = self.cache
dout = dout.reshape(dout.shape[0], 1)
dtarget_W = dout * h
self.embed.backward(dtarget_W)
dh = dout * target_W
return dh
class UnigramSampler:
def __init__(self, corpus, power, sample_size):
self.sample_size = sample_size
self.vocab_size = None
self.word_p = None
counts = collections.Counter()
for word_id in corpus:
corpus[word_id] += 1
vocab_size = len(corpus)
self.vocab_size = vocab_size
self.word_p = np.zeros(vocab_size)
for i in range(vocab_size):
self.word_p[i] = counts[i]
self.word_p = np.power(self.word_p, power)
def get_negative_sample(self, target):
batch_size = target.shape[0]
if not GPU:
negative_sample = np.zeros((batch_size, self.sample_size), dtype=np.int32)
for i in range(batch_size):
p = self.word_p.copy()
target_idx = target[i]
p[target_idx] = 0
p /= p.sum()
negative_sample[i, :] = np.random.choice(self.vocab_size, size=self.sample_size, replace=False, p=p)
else:
negative_sample = np.random.choice(self.vocab_size, size=(batch_size, self.sample_size), replace=True, p=self.word_p)
return negative_sample
class SigmoidWithLoss:
def __init__(self):
self.params, self.grads = [], []
self.loss = None
self.y = None
self.t = None
def forward(self, x, t):
self.t = t
# x = np.clip(x, -500, 500)
self.y = 1 / (1 + np.exp(-x))
self.loss = cross_entropy_error(np.c_[1 - self.y, self.y], self.t)
return self.loss
def backward(self, dout=1):
batch_size = self.t.shape[0]
dx = (self.y - self.t) * dout / batch_size
return dx
class NegativeSamplingLoss:
def __init__(self, vocab_size, embedding_dim, corpus, power=0.75, sample_size=5):
self.sample_size = sample_size
self.sampler = UnigramSampler(corpus, power, sample_size)
self.loss_layers = [SigmoidWithLoss() for _ in range(sample_size + 1)]
self.embed_dot_layers = [EmbeddingDot(vocab_size, embedding_dim) for _ in range(sample_size + 1)]
self.params, self.grads = [], []
for layer in self.embed_dot_layers:
self.params += layer.params
self.grads += layer.grads
def forward(self, h, target):
batch_size = target.shape[0]
negative_sample = self.sampler.get_negative_sample(target)
score = self.embed_dot_layers[0].forward(h, target)
correct_label = np.ones(batch_size, dtype=np.int32)
loss = self.loss_layers[0].forward(score, correct_label)
negative_label = np.zeros(batch_size, dtype=np.int32)
for i in range(self.sample_size):
negative_target = negative_sample[:, i]
negative_target = np.clip(negative_target, 0, vocab_size - 1)
score = self.embed_dot_layers[1 + i].forward(h, negative_target)
loss += self.loss_layers[1 + i].forward(score, negative_label)
return loss
def backward(self, dout=1):
dh = 0
for l0, l1 in zip(self.loss_layers, self.embed_dot_layers):
dscore = l0.backward(dout)
dh += l1.backward(dscore)
return dh
def cross_entropy_error(y, t):
if y.ndim == 1:
t = t.reshape(1, t.size)
y = y.reshape(1, y.size)
if t.size == y.size:
t = t.argmax(axis=1)
batch_size = y.shape[0]
return -np.sum(np.log(y[np.arange(batch_size), t] + 1e-7)) / batch_size
class Adam:
def __init__(self, lr=0.001, beta1=0.9, beta2=0.999):
self.lr = lr
self.beta1 = beta1
self.beta2 = beta2
self.iter = 0
self.m = None
self.v = None
def update(self, params, grads):
if self.m is None:
self.m, self.v = {}, {}
# for key, val in params.items():
for key, val in params.items():
self.m[key] = np.zeros_like(val)
self.v[key] = np.zeros_like(val)
self.iter += 1
lr_t = self.lr * np.sqrt(1.0 - self.beta2 ** self.iter) / (1.0 - self.beta1 ** self.iter)
for key in params.keys():
self.m[key] = self.beta1 * self.m[key] + (1 - self.beta1) * grads[key]
self.v[key] = self.beta2 * self.v[key] + (1 - self.beta2) * (grads[key] ** 2)
params[key] -= lr_t * self.m[key] / (np.sqrt(self.v[key]) + 1e-7)
def preprocess(text):
text = text.lower()
text = text.replace('.', ' .')
words = text.split(' ')
word_to_id = {}
id_to_word = {}
for word in words:
if word not in word_to_id:
new_id = len(word_to_id)
word_to_id[word] = new_id
id_to_word[new_id] = word
corpus = np.array([word_to_id[w] for w in words])
return corpus, word_to_id, id_to_word
def convert_one_hot(corpus, vocab_size):
N = corpus.shape[0]
if corpus.ndim == 1:
one_hot = np.zeros((N, vocab_size), dtype=np.int32)
for idx, word_id in enumerate(corpus):
one_hot[idx, word_id] = 1
elif corpus.ndim == 2:
C = corpus.shape[1]
one_hot = np.zeros((N, C, vocab_size), dtype=np.int32)
for idx_0, word_id in enumerate(corpus):
for idx_1, word_id in enumerate(word_id):
one_hot[idx_0, idx_1, word_id] = 1
return one_hot
def create_contexts_target(corpus, window_size=1):
target = corpus[window_size:-window_size]
contexts = []
for idx in range(window_size, len(corpus)-window_size):
cs = []
for t in range(-window_size, window_size + 1):
if t == 0:
continue
cs.append(corpus[idx + t])
contexts.append(cs)
return np.array(contexts), np.array(target)
lr = 0.0001
epochs = 1000
batch_size = 10
window_size = 1
sample_size = 5
text = 'You say goodbye and I say hello.'
corpus, word_to_id, id_to_word = preprocess(text)
vocab_size = len(word_to_id)
contexts, target = create_contexts_target(corpus, window_size)
W = np.random.randn(vocab_size, 10) * 0.01
negative_sampling_loss = NegativeSamplingLoss(vocab_size, 10, corpus, sample_size=5)
adam = Adam(lr=lr)
params = {}
grads = {}
losses = []
for epoch in range(epochs):
total_loss = 0
for i in range(0, len(contexts), batch_size):
context_batch = contexts[i:i + batch_size]
target_batch = target[i:i + batch_size]
h = np.mean(W[context_batch], axis=1)
loss = negative_sampling_loss.forward(h, target_batch)
# backpropagation
dout = 1
negative_sampling_loss.backward(dout)
adam.update(params, grads)
total_loss += loss
avg_loss = total_loss / (len(contexts) / batch_size)
losses.append(avg_loss)
if (epoch + 1) % 100 == 0:
print(f'Epoch {epoch + 1}/{epochs}, Loss: {avg_loss}')
plt.plot(range(1, epochs + 1), losses)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Negative Sampling')
plt.show()
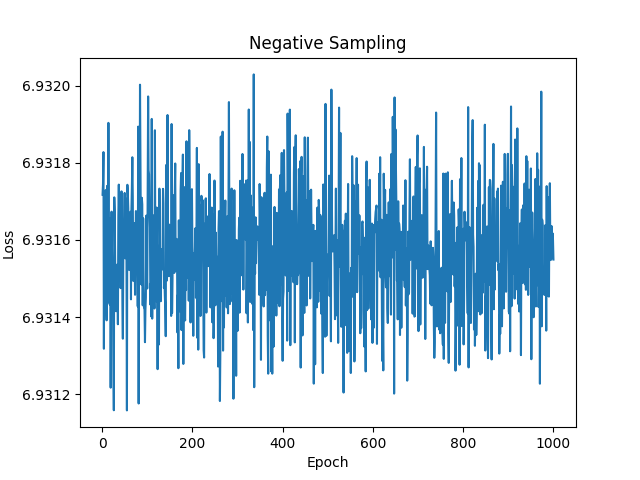
ほとんど学習できていませんが、これはコーパスが小規模すぎることが原因である可能性があります。
一般にCBoWなどと比べてNegative Samplingはデータセットに敏感な傾向があります。これは負例のサンプリングにおいて偏りが生じやすくなり学習が不安定になるためです。また、負例と正例が重なる可能性が高く、モデルが正確に区別するのが難しくなります。
■おわりに
今回はソフトマックスによる計算コストの増大を解消するために、これを改良して負例をいくつか計算することで確率分布を近似的に学習できるNegative Samplingを実装しました。
■参考文献
- Andreas C. Muller, Sarah Guido. Pythonではじめる機械学習. 中田 秀基 訳. オライリー・ジャパン. 2017. 392p.
- 斎藤 康毅. ゼロから作るDeep Learning Pythonで学ぶディープラーニングの理論と実装. オライリー・ジャパン. 2016. 320p.
- 斎藤 康毅. ゼロから作るDeep Learning② 自然言語処理編. オライリー・ジャパン. 2018. 432p.
- ChatGPT. 4o mini. OpenAI. 2024. https://chatgpt.com/
- API Reference. scikit-learn.org. https://scikit-learn.org/stable/api/index.html
- PyTorch documentation. pytorch.org. https://pytorch.org/docs/stable/index.html
- Keiron O’Shea, Ryan Nash. An Introduction to Convolutional Neural Networks. https://ar5iv.labs.arxiv.org/html/1511.08458
- API Reference. scipy.org. 2024. https://docs.scipy.org/doc/scipy/reference/index.html