AIって結局何なのかよく分からないので、とりあえず100日間勉強してみた Day74
経緯についてはこちらをご参照ください。
■本日の進捗
- Data Augmentationを理解
■はじめに
今回も「ゼロから作るDeep Learning Pythonで学ぶディープラーニングの理論と実装(オライリー・ジャパン)」で、深層学習を学んでいきます。
今回は小規模なデータセットを十分に大きな規模に拡張する手法を学びたいと思います。
■Data Augmentation
Data Augmentation(データ拡張)とは、訓練データの数を人工的に増やす手法です。特に画像認識や音声認識などのコンピュータビジョンタスクに効果的で、有意なデータを集めることが困難な場合のデータ不足解消や、それによる過学習の抑制に有効で、汎化性能の高いニューラルネットワークモデルを構築することが可能になります。
画像認識の場合には、元のデータに対して、回転、並進、スケーリング、反転、せん断変換、ズーム、ぼかし、ノイズ、色彩調整などの拡張手法を用いることがあります。
ただし、数字や文字を反転させたり、建物や景色を回転させたり、顔をせん断させたりする場合には、現実と乖離することから良い訓練データとは言えない可能性が十分に考えられるので注意が必要です。
手作業で全ての画像を回転させるのはあまりに大変ですが、SciPyのrotate関数を用いると簡単に実装することができます。
from scipy.ndimage import rotate rotated_image = rotate(input_image, angle, reshape=True, mode='nearest', cval=0.0)
rotate関数はndimageモジュールに含まれていて、下記のパラメータで制御できます。
●input_image
回転させる画像を2次元のNumPy配列で指定します
●angle
回転角度 [deg]です
●reshape
回転後の画像サイズを調整するかどうかをBooleanで指定します
●mode
ピクセルの補間方法で、回転によって不足したピクセルを埋める手法を指定します
‘nearest’ :最も近いピクセルの値で補間(デフォルト)
‘reflect’ :エッジの反射で補間
‘constant’ :指定した定数で補間
●cval
mode=’constant’の場合に定数を指定します
デフォルトは0.0
実際に(諸事情によりCNNではない通常の)ニューラルネットワークに実装してその効果を見てみます。ミニバッチとして10枚だけを無作為(再現性のためにランダムシードは設定)に抽出して、その10枚だけで学習させる訓練データが不足したモデルと、画像を左右15°回転させて3倍(30枚)に拡張したモデルで比較してみます。
import sys
import numpy as np
import matplotlib.pyplot as plt
sys.path.append("./")
from work.mnist import load_mnist
from scipy.ndimage import rotate
class ReLU:
def __init__(self):
self.mask = None
def forward(self, x):
self.mask = (x <= 0)
out = np.maximum(0, x)
return out
def backward(self, dout):
dout[self.mask] = 0
dx = dout
return dx
class Affine:
def __init__(self, W, b):
self.W = W
self.b = b
self.x = None
self.dW = None
self.db = None
def forward(self, x):
self.x = x
out = np.dot(x, self.W) + self.b
return out
def backward(self, dout):
self.dW = np.dot(self.x.T, dout)
self.db = np.sum(dout, axis=0)
dx = np.dot(dout, self.W.T)
return dx
class SoftmaxCrossEntropy:
def __init__(self):
self.output = None
self.grad_input = None
def forward(self, logits):
exp_values = np.exp(logits - np.max(logits, axis=1, keepdims=True))
self.output = exp_values / np.sum(exp_values, axis=1, keepdims=True)
return self.output
def backward(self, y_true):
self.grad_input = self.output - y_true
return self.grad_input
def cross_entropy_error(y, t):
delta = 1e-7
return -np.sum(t * np.log(y + delta)) / y.shape[0]
class NeuralNetwork:
def __init__(self, input_size, hidden_size, output_size, weight_init_std=0.01):
self.params = {}
self.params['W1'] = weight_init_std * np.random.randn(input_size, hidden_size)
self.params['b1'] = np.zeros(hidden_size)
self.params['W2'] = weight_init_std * np.random.randn(hidden_size, hidden_size)
self.params['b2'] = np.zeros(hidden_size)
self.params['W3'] = weight_init_std * np.random.randn(hidden_size, output_size)
self.params['b3'] = np.zeros(output_size)
self.layers = [
Affine(self.params['W1'], self.params['b1']),
ReLU(),
Affine(self.params['W2'], self.params['b2']),
ReLU(),
Affine(self.params['W3'], self.params['b3'])
]
self.loss_layer = SoftmaxCrossEntropy()
def forward(self, x):
for layer in self.layers:
x = layer.forward(x)
return x
def compute_loss(self, x, y_true):
logits = self.forward(x)
loss = cross_entropy_error(self.loss_layer.forward(logits), y_true)
return loss
def backward(self, y_true):
dout = self.loss_layer.backward(y_true)
for layer in reversed(self.layers):
dout = layer.backward(dout)
def update(self, lr):
for layer in self.layers:
if isinstance(layer, Affine):
layer.W -= lr * layer.dW
layer.b -= lr * layer.db
(X_train, y_train), (X_test, y_test) = load_mnist(normalize=True, one_hot_label=True)
def augment_data(X, y, angles=[15, -15]):
X_augmented = []
y_augmented = []
for img, label in zip(X, y):
X_augmented.append(img)
y_augmented.append(label)
img_reshaped = img.reshape(28, 28)
for angle in angles:
img_rotated = rotate(img_reshaped, angle, reshape=False, mode='nearest')
X_augmented.append(img_rotated.flatten())
y_augmented.append(label)
return np.array(X_augmented), np.array(y_augmented)
X_train_augmented, y_train_augmented = augment_data(X_train, y_train)
train_size = X_train_augmented.shape[0]
batch_size = 10
np.random.seed(8)
batch_mask = np.random.choice(train_size, batch_size)
X_batch = X_train_augmented[batch_mask]
y_batch = y_train_augmented[batch_mask]
lr = 0.001
step_num = 4000
input_size = 784
hidden_size = 200
output_size = 10
network = NeuralNetwork(input_size, hidden_size, output_size)
loss_history = []
for i in range(step_num):
loss = network.compute_loss(X_batch, y_batch)
loss_history.append(loss)
network.backward(y_batch)
network.update(lr)
print(f"Step {i+1}, Loss: {loss}")
plt.plot(range(1, step_num + 1), loss_history)
plt.xlabel("Step")
plt.ylabel("cross entropy loss")
plt.title("Backpropagation SGD with Data Augmentation")
plt.show()
fig, axes = plt.subplots(3, 10, figsize=(15, 5))
axes = axes.flatten()
for i in range(30):
axes[i].imshow(X_train_augmented[i].reshape(28, 28), cmap='gray')
axes[i].axis('off')
plt.tight_layout()
plt.show()
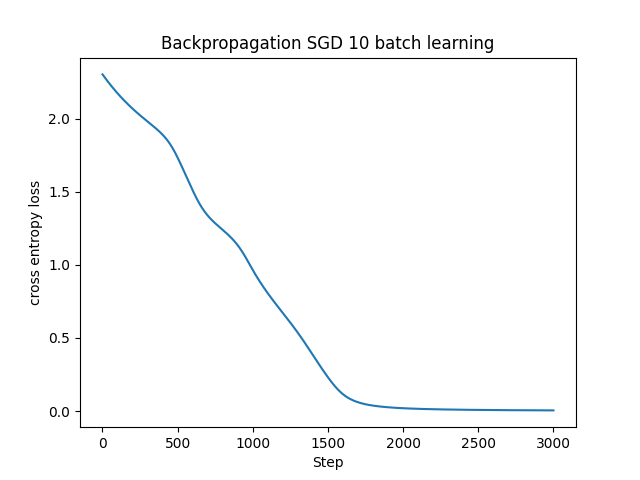
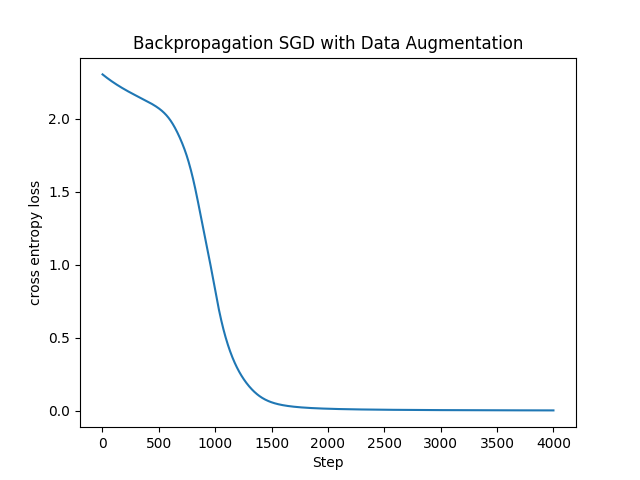
左図は訓練データが10枚のみなので学習に時間がかかっています。(汎化性能という意味で)まともなモデルにはなっていないと思われます。Data Augmentationを適用した30枚のデータでもまだまだ足りなくて学習に時間がかかってはいますが、10枚の場合よりは(およそ500ステップくらい?)早く収束するように改善しています。
実際に生成された画像も見てみます。

元の無作為に選ばれた10枚(これはData Augmentationを適用していないモデルで用いた画像と同じです)に、左右に15°回転を加えた20枚を足した30枚の訓練データになります。
15°程度の回転であれば、(1はだいぶ怪しいですが,,,)おおよそあり得そうな画像になっているので問題ないかなと思います。元が10枚なのでたまたま1と4が多く偏っていますが、データが増えたことで特徴を学習しやすくなったのかと思います。ただし、元の画像に対して(ピクセル単位では別物ですが)ほぼ同じ画像の比率が高いので、過学習という観点では気を付けないといけません。
■おわりに
今回はData Augmentationの一例として軽微な回転を行い、元のデータに付け足すデータ拡張による効果を確認してみました。このコードではモデルの学習よりも画像を回転して保持する方が時間がかかっています。実運面ではもう少し調整した方がいいかもしれないです。
また、参考文献を読了しましたので、今回で画像認識におけるニューラルネットワークをひと段落したいと思います。
引き続き、題材を変えてDeep Learningを”勉強”していきます。
■参考文献
- Andreas C. Muller, Sarah Guido. Pythonではじめる機械学習. 中田 秀基 訳. オライリー・ジャパン. 2017. 392p.
- 斎藤 康毅. ゼロから作るDeep Learning Pythonで学ぶディープラーニングの理論と実装. オライリー・ジャパン. 2016. 320p.
- ChatGPT. 4o mini. OpenAI. 2024. https://chatgpt.com/
- API Reference. scikit-learn.org. https://scikit-learn.org/stable/api/index.html
- PyTorch documentation. pytorch.org. https://pytorch.org/docs/stable/index.html
- Keiron O’Shea, Ryan Nash. An Introduction to Convolutional Neural Networks. https://ar5iv.labs.arxiv.org/html/1511.08458
- API Reference. scipy.org. 2024. https://docs.scipy.org/doc/scipy/reference/index.html