AIって結局何なのかよく分からないので、とりあえず100日間勉強してみた Day5
経緯についてはこちらをご参照ください。
Pandas User Guideを読んでみた #2 はこちらをご参照ください。
■本日の進捗
●Pandas User Guideを勉強
■10 minutes to pandas
前回の続きから学んでいきたいと思います。
●Join
まずはJoinから。
なんと、merge()を使えばSQLライクな結合ができるみたいです!すごい!
SQLを使ったことないんですけどね。
User Guide通りに入力していくとこんな感じ
>>> left = pd.DataFrame({"key": ["foo", "foo"], "lval": [1, 2]})
>>> right = pd.DataFrame({"key": ["foo", "foo"], "rval": [4, 5]})
>>>
>>> left
key lval
0 foo 1
1 foo 2
>>> right
key rval
0 foo 4
1 foo 5
>>>
>>> pd.merge(left, right, on="key")
key lval rval
0 foo 1 4
1 foo 1 5
2 foo 2 4
3 foo 2 5
>>>fooというインデックスにそれぞれ1, 2と4, 5が対応しているデータをfooで結合すると、1-4, 1-5, 2-4, 2-5というデータができる。
#merge-typesによるとこれはデカルト積(Cartesian product)を行っているということなので、すべての対からなる集合を作っているのであろうと思う。つまりlvalとrvalのすべての組み合わせを生成した結果を返している。
ちなみにlvalとrvalはLeft-ValueとRight-Valueのことだと思うが、fooってなんやねん
●未来を積み上げよう
stack()の紹介の中に下記のコマンドを実行している表記がある。
stacked = df2.stack(future_stack=True)
しかし結果は次のように返ってきた。
>>> df2
A B
first second
bar one -0.760201 1.510770
two 0.223064 0.128883
baz one 0.813229 1.535207
two -0.738731 0.257753
>>>
>>> stacked = df2.stack(future_stack=True)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: stack() got an unexpected keyword argument 'future_stack'
>>>
>>> pd.__version__
'1.2.0'
>>>原因は実行環境のバージョンが古いためだったので最新の環境で実行したらすんなり通った。(こういう大したことない作業は平日にわざわざメインPCを起動しないのが裏目に出たのだが、偶発的に新しめの機能だということを知れた。)
>>> stacked = df2.stack(future_stack=True)
>>>
>>> stacked
first second
bar one A -0.650775
B 1.025571
two A -0.652445
B 0.494915
baz one A 1.055400
B 1.971699
two A 0.994383
B 0.521073
dtype: float64
>>>
>>> pd.__version__
'2.2.2'
>>>それはともかく、これほどまでに興味を惹かざるを得ないfuture_stackとかいう名前の引数は一体何なんだろうか。stackのページには下記の説明がある。
future_stackbool, default False
Whether to use the new implementation that will replace the current implementation in pandas 3.0. When True, dropna and sort have no impact on the result and must remain unspecified. See pandas 2.1.0 Release notes for more details.
pandas 3.0でstack()の新メソッドが導入される予定で、これをTrueにすればお試しできるけど、dropnaとsortの引数は無視されるので書かないでくれよな。と言ってます。
つまりカラムをインデックスの階層に変換して再構築してくれているみたいです。
●Pivot Table
これはとても簡単です。
>>> df
A B C D E
0 one A foo -1.273484 0.057966
1 one B foo -0.325936 0.806955
2 two C foo 0.173713 0.315791
3 three A bar -1.244057 0.170635
4 one B bar -1.872533 -1.308601
5 one C bar -1.310628 -1.126034
6 two A foo 0.257776 -1.809870
7 three B foo 0.537365 -2.035669
8 one C foo -0.649512 -0.705118
9 one A bar -1.906951 0.065853
10 two B bar -0.127145 -0.518007
11 three C bar -0.180493 0.358961
>>>
>>> pd.pivot_table(df, values="D", index=["A", "B"], columns=["C"])
C bar foo
A B
one A -1.906951 -1.273484
B -1.872533 -0.325936
C -1.310628 -0.649512
three A -1.244057 NaN
B NaN 0.537365
C -0.180493 NaN
two A NaN 0.257776
B -0.127145 NaN
C NaN 0.173713
>>>D列の値をインデックスにAとB、カラムにCを取って変換しています。
●Time Series
詳細はUser Guide(#time-series)に書いてあります。
日時が入ったデータフレームの時刻変換できるSeries.tz-localize()とSeries.tz_convert()の組み合わせがめちゃくちゃ便利そうだったので、いよいよチャンピオンシップも佳境に来た今週末のFormula 2のタイムテーブルに適用してその実力を見てみようと思います。
(F1公式のスケジュールは便利だけど、F2公式はタイムテーブルがLocal timeしか表示してくれないから見づらいことこの上ないんですよね…)
まずはデータの入力ですが、これは公式サイトに載っているので実運用するなら簡単に自動化できるでしょう。今回は手入力(コピペです)。
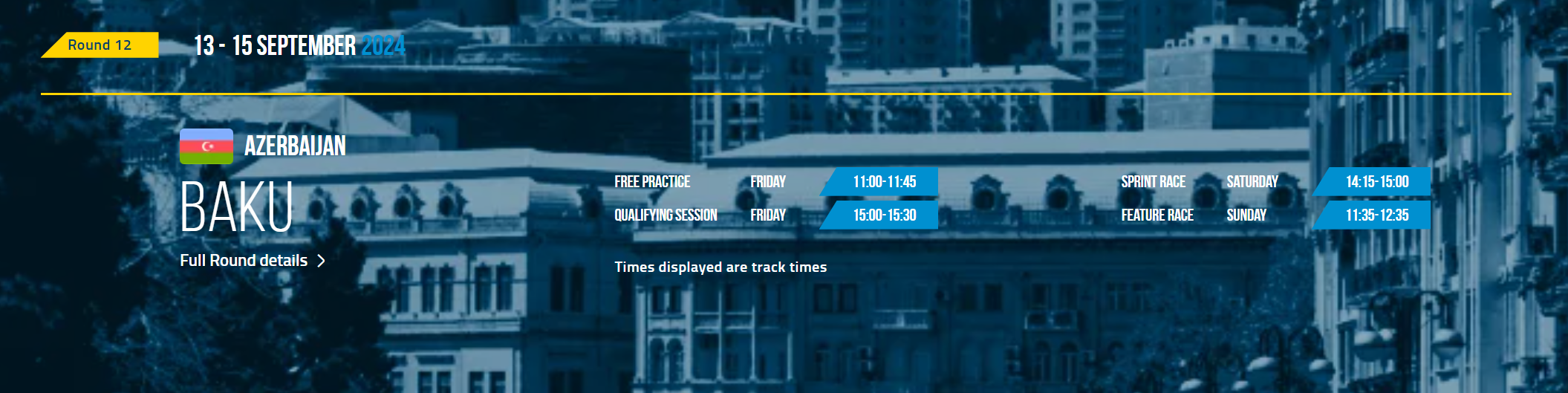
>>> data = {
... 'AZT': [
... '2024-09-13 11:00:00',
... '2024-09-13 11:45:00',
... '2024-09-13 15:00:00',
... '2024-09-13 15:30:00',
... '2024-09-14 14:15:00',
... '2024-09-14 15:00:00',
... '2024-09-15 11:35:00',
... '2024-09-15 12:35:00'
... ]
... }これをアゼルバイジャン(現在2024年9月13日、レースウィークです!!!)現地時間にしてから日本時間にコンバートしていきます。
>>>
>>> f2df = pd.DataFrame(data)
>>> f2df['AZT'] = pd.to_datetime(f2df['AZT'])
>>> f2df['AZT'] = f2df['AZT'].dt.tz_localize('Asia/Baku')
>>>
>>> f2df['JST'] = f2df['AZT'].dt.tz_convert('Asia/Tokyo')
>>> f2df
AZT JST
0 2024-09-13 11:00:00+04:00 2024-09-13 16:00:00+09:00
1 2024-09-13 11:45:00+04:00 2024-09-13 16:45:00+09:00
2 2024-09-13 15:00:00+04:00 2024-09-13 20:00:00+09:00
3 2024-09-13 15:30:00+04:00 2024-09-13 20:30:00+09:00
4 2024-09-14 14:15:00+04:00 2024-09-14 19:15:00+09:00
5 2024-09-14 15:00:00+04:00 2024-09-14 20:00:00+09:00
6 2024-09-15 11:35:00+04:00 2024-09-15 16:35:00+09:00
7 2024-09-15 12:35:00+04:00 2024-09-15 17:35:00+09:00
>>>これで変換は完了しました。果たして合ってるのでしょうか?
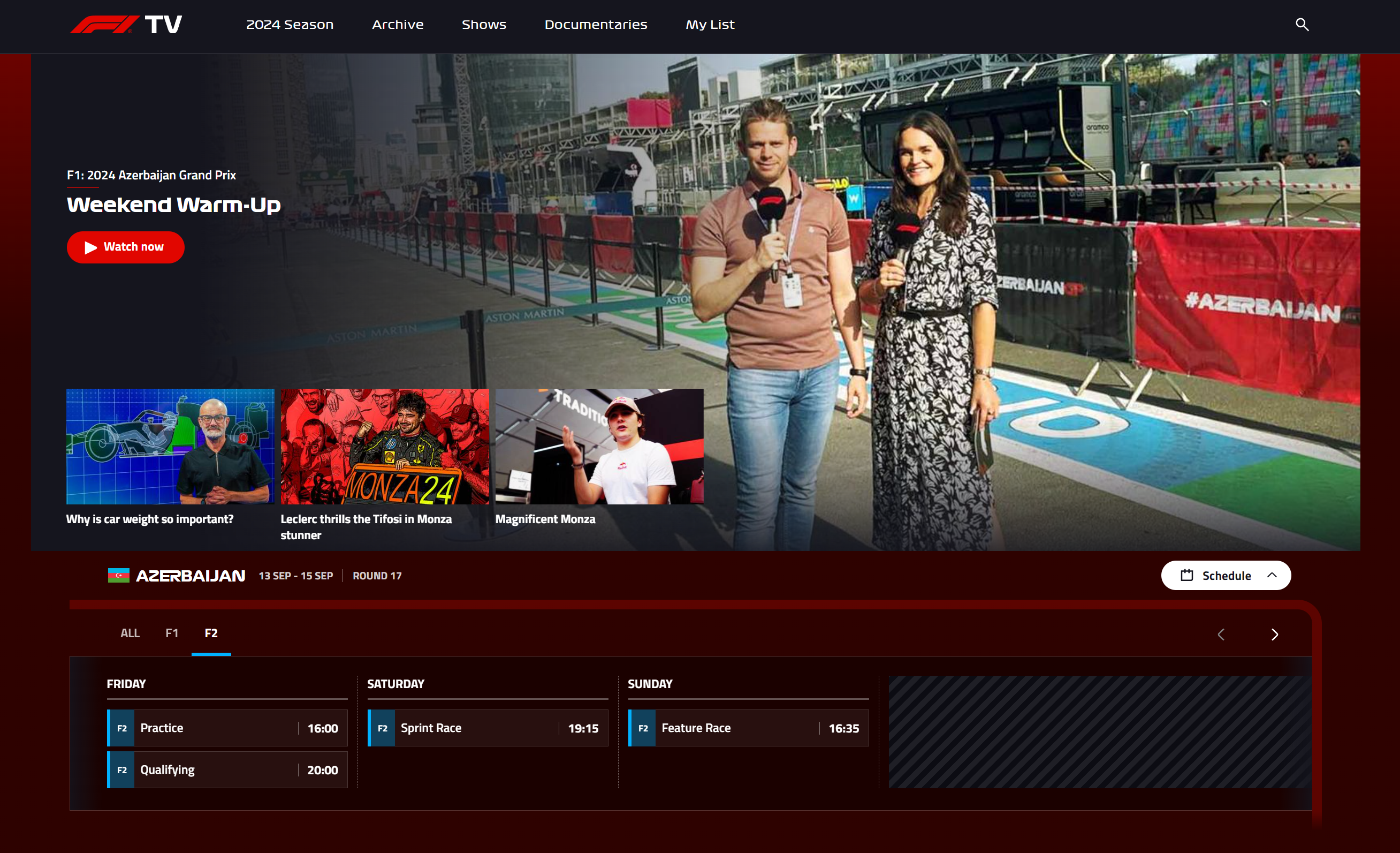
素晴らしい…全セッション見事に日本時間にコンバートされていました。
これでもうF1TVにアクセスする必要はないですね()
余談
ご存じない方もいるかもしれないので本題から逸れますが、F1TVはこの世で最も有用で教育的でエンターテインメントで感動的なWebサイトです。タイムテーブルはサポートレースもすべて(今週末はF2だけですが、F3もPSCもF1Aも)網羅されていて最初から日本時間に変換済みの至れり尽くせり仕様です。無料会員でもタイムテーブルとハイライトを含む一部の動画は見れたはずですので、この機会に是非入会のご検討を。
●お勉強を頑張っても生まれ持った名前には勝てないの?
Categoriesのソートに関してです。
>>> df["grade"] = df["grade"].cat.set_categories(
... ["very bad", "bad", "medium", "good", "very good"]
... )
>>>
>>> df
id raw_grade grade
0 1 a very good
1 2 b good
2 3 b good
3 4 a very good
4 5 a very good
5 6 e very bad
>>> df.sort_values(by="grade")
id raw_grade grade
5 6 e very bad
1 2 b good
2 3 b good
0 1 a very good
3 4 a very good
4 5 a very good
>>>id順(勝手に名前順と想定)に並んだ表を成績順にソートしています。
この順序になるのは事前に序列を指定しているからですが、元の順番も恐らく保持されていて、good同士、very good同士の順番はid順を保っているのだと理解しました。
●出力と入力
お恥ずかしながら、df.to_parquet()のParquetフォーマットというのを存じ上げなかったので聞いてみました。

データレイクで使われるみたいですね。覚えておいた方が良さそうです。
●DataFrameの使用メモリ
df.info()でDataFrameが確保しているメモリ使用量を確認できるようです。
>>> df.info(memory_usage="deep")
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 6 entries, 0 to 5
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id 6 non-null int64
1 raw_grade 6 non-null object
2 grade 6 non-null category
dtypes: category(1), int64(1), object(1)
memory usage: 933.0 bytes
>>>メモリ管理はプログラムの基本ですね。
ちなみにNumPyは下記のnbytesで配列のメモリ使用量を表示できるみたいです。
>>> arr = np.array([1, 2, 3, 4, 5])
>>> arr.nbytes
40仕事は基本ShellScriptとVBAにすべてやらせてる民なので、VBAにも標準で実装してほしいものです。(ちなみにWindows APIやShellScriptでできますよ。)
●Nullable Integer
integer-naについてです。
前提として、整数型では欠損値(NaN)を表現できない。これは、整数型が固定ビット数(32bit, 64bit)で数字を表現しているので、非数に充てるための余裕がないからである。浮動小数点型では非数を表現するためのビット(IEEE754)の余裕があるので通常はFloatを用いている。
>>> s = pd.Series([1, 2, 3, 4, 5], index=list("abcde"))
>>> s
a 1
b 2
c 3
d 4
e 5
dtype: int64
>>>
>>> s.dtype
dtype('int64')整数を入れたSeriesはもちろんint型になっている。
>>> s2 = s.reindex(["a", "b", "c", "f", "u"])
>>> s2
a 1.0
b 2.0
c 3.0
f NaN
u NaN
dtype: float64
>>>このSeriesにfとuというインデックスを追加し欠損値を表現させると、自動的にfloat型にしてなんとかNaNを表現しようとしてくれている。(会社の解析ツールをひとりで作って管理している社畜からすると、これだけで十分賢いと思う。例外処理という意味で。)
しかしPandasはNullable Integerという整数型を用意してくれている。
#nullable-integer-data-typeによるとIntegerArrayは特殊な配列なので予告なく仕様が変わる可能性があると書いてあるので注意が必要かもしれない。
>>> s_int = pd.Series([1, 2, 3, 4, 5], index=list("abcde"), dtype=pd.Int64Dtype())
>>> s2_int = s_int.reindex(["a", "b", "c", "f", "u"])
>>> s2_int
a 1
b 2
c 3
f <NA>
u <NA>
dtype: Int64
>>>整数型のまま見事に非数を表現できている。
これは内部でマスクという内部的なフラグを保持することで実現しているらしい。上記を例に取ると、
[1, 2, 3, <NA>, <NA>] では内部的に、
[False, False, False, True, True] というマスク配列がある
非数のためのフラグ配列なので、Trueであれば非数であることに注意。
以上、Pandas User Guide : 10 minutes to pandas(と付随する参照リファレンス)を読了しました。初歩的な内容にお付き合いいただき、ありがとうございました。
■おわりに
10 minutes to pandasを3時間+α(かかりすぎだろ笑)で終了できました。
User Guideではこの次にcookbookというのもあるんですが、さらっと見た感じほとんど重複しているので飛ばそうと思います。
次回はMatplotlib 3.9.2 documentationに取り掛かります。
■参考文献
- pandas user guide – pandas v2.2.2 documentation. pandas.pydata.org. 2024. https://pandas.pydata.org/docs/user_guide/index.html
- ChatGPT. 4o mini. OpenAI. 2024.
https://chatgpt.com/